![]()
 Dubbo实战经验分享与源码分析 专栏收录该内容,点击查看专栏更多内容
Dubbo实战经验分享与源码分析 专栏收录该内容,点击查看专栏更多内容原创 吴就业 203 0 2019-12-16
本文为博主原创文章,未经博主允许不得转载。
本文链接:https://wujiuye.com/article/edfeebff057647a5b6a9a91b835f73cb
作者:吴就业
链接:https://wujiuye.com/article/edfeebff057647a5b6a9a91b835f73cb
来源:吴就业的网络日记
本文为博主原创文章,未经博主允许不得转载。
本篇文章写于2019年12月16日,从公众号|掘金|CSDN手工同步过来(博客搬家),本篇为原创文章。
上篇我们分析了服务提供者处理一个请求的全过程,当然,是跳过信息交换层和传输层的。本篇继续分析服务提供者发起一个远程RPC调用的全过程,也是跳过信息交换层和传输层,但发起请求的逻辑会复杂些,包括负载均衡和失败重试的过程,以及当消费端配置与每个服务提供端保持多个长连接时的处理逻辑。
本篇内容:
回答一个疑惑,也是我一直以来的疑惑。假设我在一个微服务中,有两个bean都依赖同一个Service(dubbo接口),那么服务引入会创建两个ReferenceBean吗?
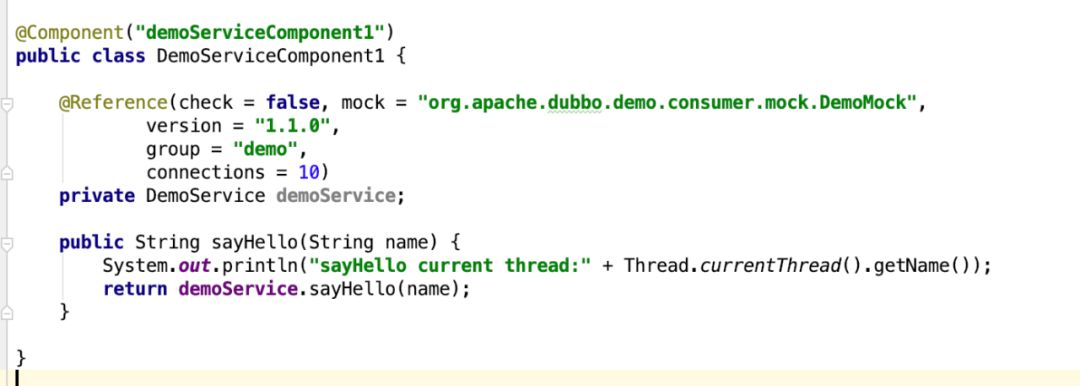
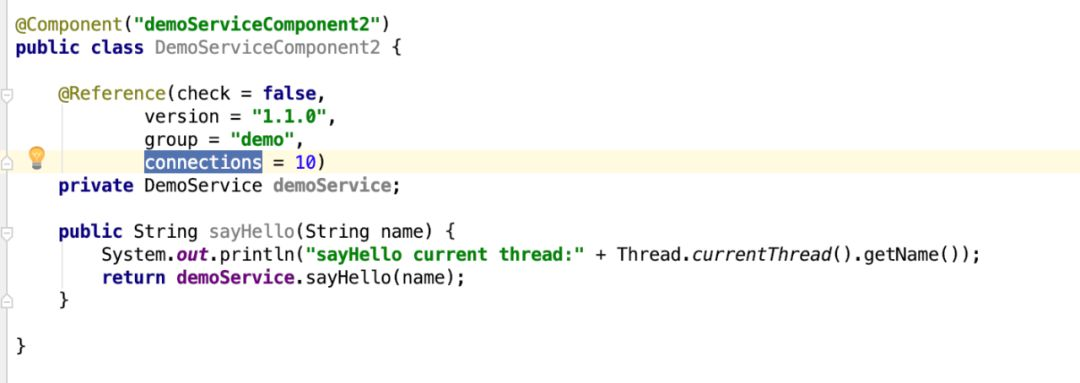
DemoServiceComponent1和DemoServiceComponent2都依赖DemoService服务。
在分析Dubbo与Spring整合时,我们已经知道,被@Reference注释的字段将由AnnotationInjectedBeanPostProcessor这个BeanPostProcessor处理,负责给bean注入依赖。看下这个BeanPostProcessor处理依赖的入口。
protected Object getInjectedObject(A annotation, Object bean, String beanName, Class<?> injectedType,
InjectionMetadata.InjectedElement injectedElement) throws Exception {
// 获取依赖注入缓存key,当key相同时,从缓存中取
// ServiceBean:org.apache.dubbo.demo.DemoService:1.1.0:demo
// #source=private org.apache.dubbo.demo.DemoService org.apache.dubbo.demo.consumer.comp.DemoServiceComponent.demoService
// #attributes={group=demo, check=false, version=1.1.0, mock=org.apache.dubbo.demo.consumer.mock.DemoMock}
String cacheKey = buildInjectedObjectCacheKey(annotation, bean, beanName, injectedType, injectedElement);
// 从缓存中获取
Object injectedObject = injectedObjectsCache.get(cacheKey);
// 缓存没有则创建
if (injectedObject == null) {
injectedObject = doGetInjectedBean(annotation, bean, beanName, injectedType, injectedElement);
// 如果缓存不存在则添加到缓存中
injectedObjectsCache.putIfAbsent(cacheKey, injectedObject);
}
return injectedObject;
}
所以,会不会为DemoServiceComponent1和DemoServiceComponent2都创建一个服务引入代理对象,是由@Reference注释配置的属性决定的。connections参数是可以忽略的,mock参数是不能忽略的,所以DemoServiceComponent1中配置mock,而DemoServiceComponent2中不配置mock就会创建不同的代理对象。至于哪些属性是不可忽略的,可自行看代码,我只关心mock和connections,因为我在项目中用到这两个参数。其它分组、版本号、是否在引入时判断提供者是否可用,这些都是决定缓存key是否相同的关键参数。
但是这里是代理对象,底层依然使用同一个ReferenceBean,且注册中心中也只存在一个消费者,而实际上,这两个代理类也没什么不一样。可以继续看doGetInjectedBean方法。
@Override
protected Object doGetInjectedBean(Reference reference, Object bean, String beanName, Class<?> injectedType,
InjectionMetadata.InjectedElement injectedElement) throws Exception {
// ServiceBean:接口名:版本号:分组
String referencedBeanName = buildReferencedBeanName(reference, injectedType);
ReferenceBean referenceBean = buildReferenceBeanIfAbsent(referencedBeanName, reference, injectedType, getClassLoader());
cacheInjectedReferenceBean(referenceBean, injectedElement);
return buildProxy(referencedBeanName, referenceBean, injectedType);
}
决定是否使用同一个ReferenceBean,只由接口名、版本号、分组决定的,与其它参数配置无关。所以,不管DemoServiceComponent1和DemoServiceComponent2的connections参数是否相同,都只会按照Spring初始化bean的顺序决定使用哪个@Reference配置的connections。
总结,拿笔记下来:只要是同一个接口、同一个版本号、同一个分组,那么不管有多少个依赖它的bean配置的@Reference的参数怎么不同,都只会使用同一个ReferenceBean对象。至于不同bean中@Reference配置的参数不同,会有哪些起作用,就取决于Spring初始化一个bean的过程。简单说,就是只有一个@Reference起作用。如果不指定Spring初始化bean的顺序,那么就给每个@Reference使用相同的属性配置,这样就确保配置都能起作用。
// 在处理bean的依赖注入时,如果字段是被@Reference注释的,
// 则处理依赖的调用链如下
1、AnnotationInjectedBeanPostProcessor#getInjectedObject
2、ReferenceAnnotationBeanPostProcessor#doGetInjectedBean
3、ReferenceAnnotationBeanPostProcessor#buildProxy
4、ReferenceAnnotationBeanPostProcessor#buildInvocationHandler
5、ReferenceAnnotationBeanPostProcessor.ReferenceBeanInvocationHandler#init
6、ReferenceConfig#init
7、ReferenceConfig#createProxy
上面当是回顾下Spring阶段的服务引入过程。在配置层ReferenceConfig调用createProxy方法开始,就进入到注册中心层的服务引入。注册中心层的服务引用也不重复分析了。
以dubbo协议为例,由注册中心委托给RegistryDirectory实现事件订阅,通过订阅获取所有可用的服务提供者,并依次调用RPC层的DubboProtocol的refer方创建Invoker实例,调用多少次就是有多少个服务提供者。
DubboProtocol的refer方法在其父类中实现。
@Override
public <T> Invoker<T> refer(Class<T> type, URL url) throws RpcException {
return new AsyncToSyncInvoker<>(protocolBindingRefer(type, url));
}
refer方法创建一个支持异步转同步的Invoker。我们先看protocolBindingRefer方法,protocolBindingRefer返回一个Invoker,由子类DubboProtocol实现,所以AsyncToSyncInvoker持有的就是DubboProtocol创建的Invoker。
@Override
public <T> Invoker<T> protocolBindingRefer(Class<T> serviceType, URL url) throws RpcException {
......
// 创建一个Invoker
DubboInvoker<T> invoker = new DubboInvoker<T>(serviceType, url, getClients(url), invokers);
invokers.add(invoker);
return invoker;
}
protocolBindingRefer创建一个DubboInvoker,只负责RPC层的调用。由于任何远程调用都是异步的,所以异步转同步的逻辑由AsyncToSyncInvoker实现。看下AsyncToSyncInvoker的invoke方法。
@Override
public Result invoke(Invocation invocation) throws RpcException {
Result asyncResult = invoker.invoke(invocation);
try {
// 判断是否同步调用
if (InvokeMode.SYNC == ((RpcInvocation)invocation).getInvokeMode()) {
// 调用get方法阻塞当前线程,直接接收响应
asyncResult.get();
}
} catch (InterruptedException e) {
......
}
return asyncResult;
}
调用Invoker的invoke方法返回的Result实际上是一个Future,然后根据@Reference配置的属性,看下是否声明为同步调用,默认true,如果是,则调用Result的get方法,开始阻塞当前线程,直接接收到服务端的返回。异常则抛出一个RpcException。因为此处的Invoker也是经过层层包装的,上层会处理异常,比如Mock 机制。
AsyncToSyncInvoker包装了DubboInvoker,那么DubboInvoker包装的是什么呢?为何调用它的invoke方法就能调用远端服务呢?
DubboInvoker<T> invoker = new DubboInvoker<T>(serviceType, url,
getClients(url), invokers);
在new DubboInvoker时,调用getClients(url)方法获取远程连接,这里将涉及到信息交换层,我们只会分析到这里。
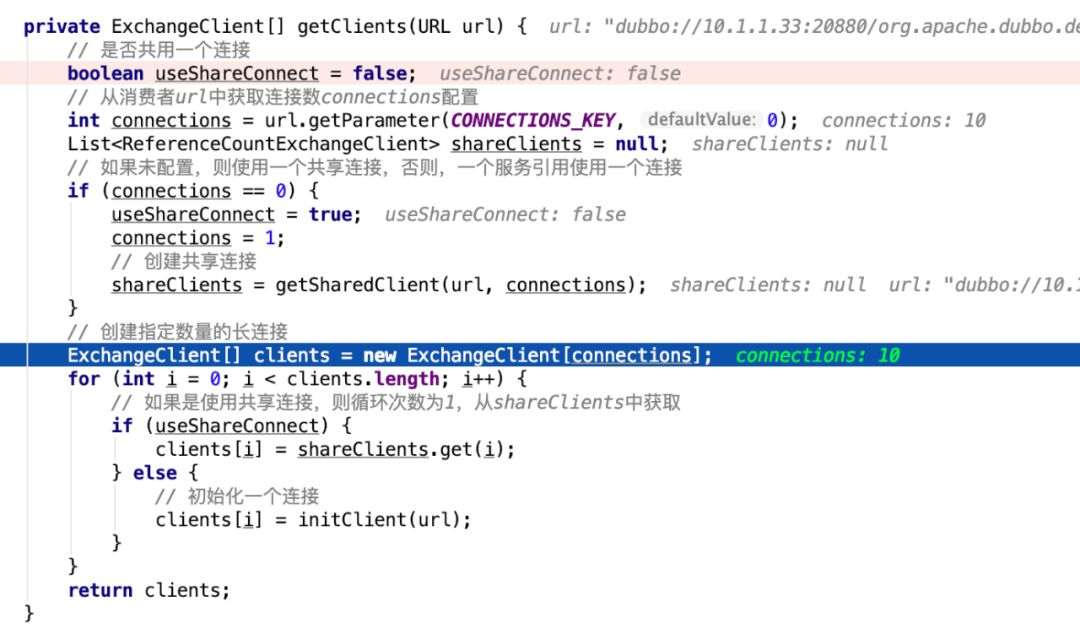
图为debug下断点的截图,能够看到,当前我配置的连接数为10,所以会创建10个ExchangeClient对象,这10个ExchangeClient是什么时候被使用的,稍后分析。
在new DubboInvoker时,除了调用getClients方法获取远程连接ExchangeClient之外,还给DubboInvoker传入了一个对象,就是invokers,这个invokers是DubboProtocol的一个字段,每创建一个DubboInvoker都会将其加入到这个字段中,所以每个DubboInvoker都能拿到所有的DubboInvoker。
DubboInvoker<T> invoker = new DubboInvoker<T>(serviceType, url, getClients(url), invokers);
invokers.add(invoker);
那么要分析服务消费端发起一次远程调用,就可以从这个DubboInvoker的invoker方法下断点。在此之前的调用路径先不分析。 【org.apache.dubbo.rpc.protocol.dubbo.DubboInvoker#doInvoke】
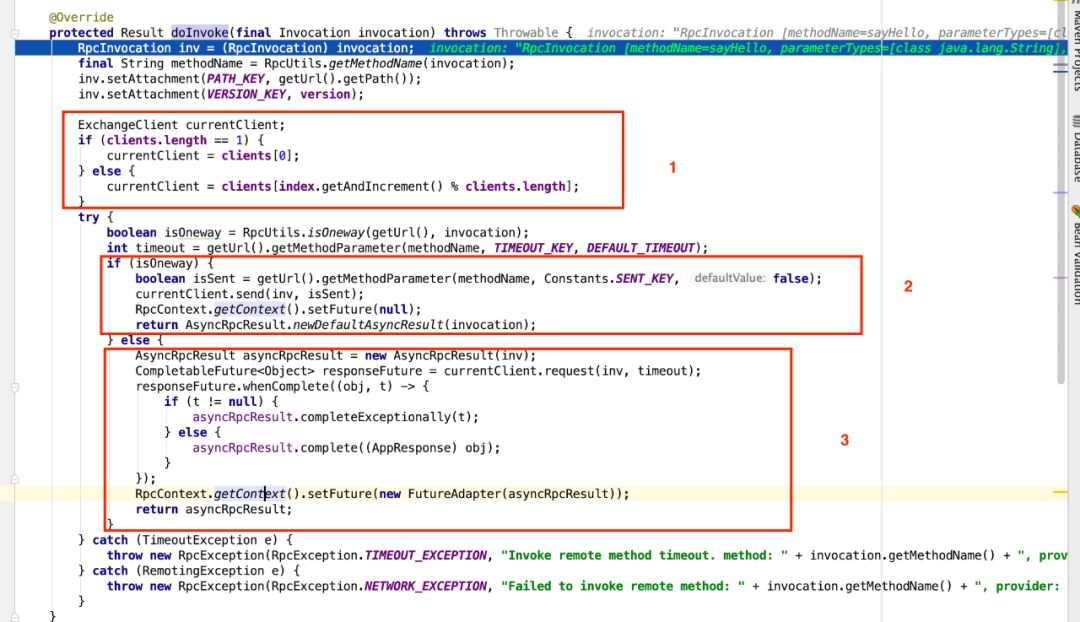
例子中我给@Reference配置的连接数为10个,所以将会从10个连接中,通过当前调用次数与10取模,选出本次调用将要使用的长连接,说白了就是轮询。对应图中红框1部分代码。至于这个长连接数配置多少个合适,我也给不出一个准确的答案,就算配置一个也没多大问题,因为请求转为数据包发送出去之后,就不占用连接了。而等待服务端响应结果是NIO非阻塞模式等待的。消费端之所以能知道哪次响应是当前请求的响应,是通过在请求头中添加一个请求id识别的,服务端响应时也带上该请求id,后面分析传输层源码时介绍。
而图中2和3部分的代码是分别处理请求是否需要获取返回结果,即从url中获取return参数是否为true,比如
@Reference(check = false, mock = "org.apache.dubbo.demo.consumer.mock.DemoMock",
version = "1.1.0",
group = "demo",
// isReturn=false时,不会创建Future
methods = {@Method(name = "sayHello", isReturn = true, async = true, sent = true)})
private DemoService demoService;
配置中指定sayHello方法不获取返回值,那么isOneway就为false,否则为true。当不需要获取返回值时,调用RpcContext.getContext().setFuture(null)设置当前线程上下文的Future为null,也就没办法通过RpcContext获取返回值。所以通过分析源码,我们能够知道很多配置的作用,以及怎么去用。
前面我们直接分析了RPC层的DubboInvoker的invoke方法,但似乎漏掉了很多内容,比如负载均衡呢?
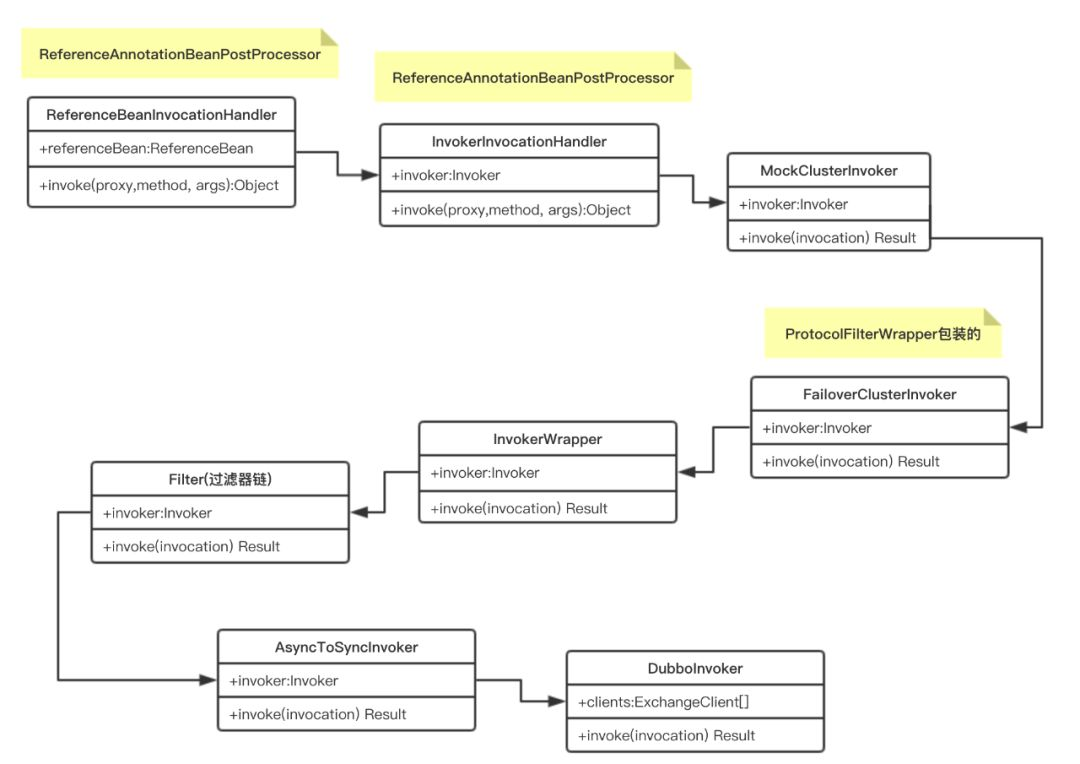
现在我们从ReferenceBeanInvocationHandler开始分析,这是一个InvocationHandler,就是jdk动态代理的InvocationHandler。而ReferenceBeanInvocationHandler是在Spring初始化bean过程中,由ReferenceAnnotationBeanPostProcessor处理依赖注入时,创建一个ReferenceBean的代理对象时创建的,由于是使用jdk动态代理,所以你应该知道ReferenceBeanInvocationHandler的作用。
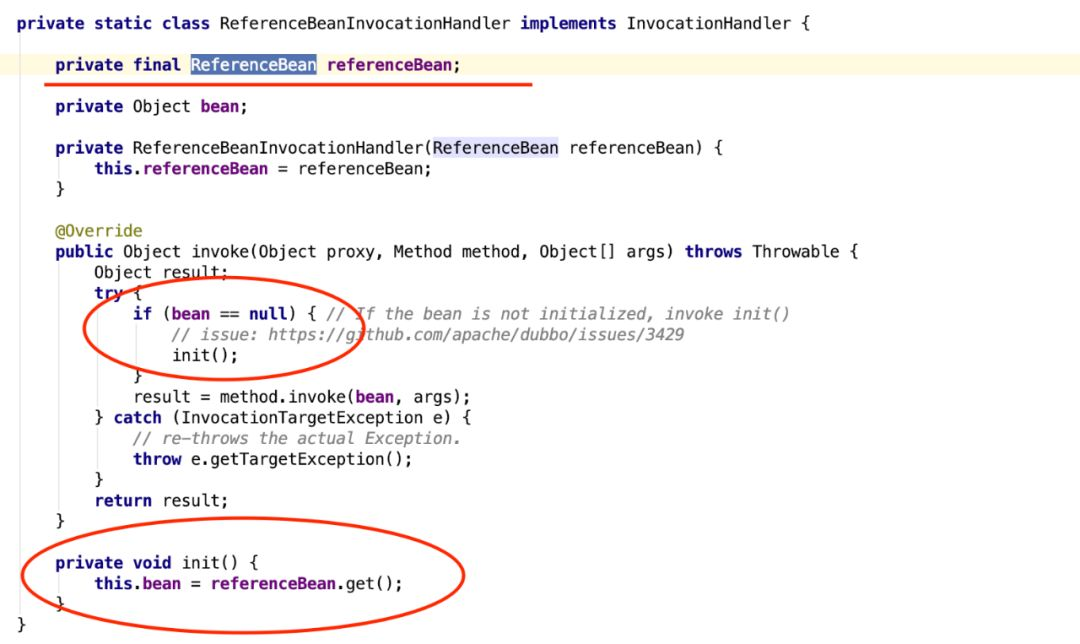
ReferenceBeanInvocationHandler代理的是ReferenceBean,但是ReferenceBean是一个FactoryBean,所以是代理ReferenceBean.getObject返回的对象。
InvokerInvocationHandler则是在配置层ReferenceConfig的createProxy方法中,使用javassist代理的由注册中心层返回的Invoker。代理来代理去的确实绕得很。
配置层ReferenceConfig调用注册中心层的refer方法引入服务。
private <T> Invoker<T> doRefer(Cluster cluster, Registry registry, Class<T> type, URL url) {
// 创建一个注册目录
RegistryDirectory<T> directory = new RegistryDirectory<T>(type, url);
.........
Invoker invoker = cluster.join(directory);
// ProviderConsumerRegTable.registerConsumer(invoker, url, subscribeUrl, directory);
return invoker;
}
在RegistryProtocol的refer方法中,RegistryDirectory由Cluster的join方法转为Invoker,这里会比较难以理解,因为服务提供者是有多个的,而且是会改变的,所以不能像服务导出那样,一条链路无缝衔接。这里只能返回一个抽象的Invoker,只有在RegistryDirectory订阅到提供者时,才会生成具体的Invoker。
这个cluster默认为FailoverCluster。
public class FailoverCluster implements Cluster {
public final static String NAME = "failover";
@Override
public <T> Invoker<T> join(Directory<T> directory) throws RpcException {
return new FailoverClusterInvoker<T>(directory);
}
}
但是这个FailoverCluster会被包装成MockClusterWrapper。Cluster的join方法被声明为自适应扩展点机制,由于我们并没有配置cluster,所以默认是FailoverCluster。
但为什么会被包装成MockClusterWrapper呢?这就是SPI自适应扩展机制最另人捉狂的地方。先看下dubbo-cluster模块下的resources目录下的org.apache.dubbo.rpc.cluster.Cluster配置文件。
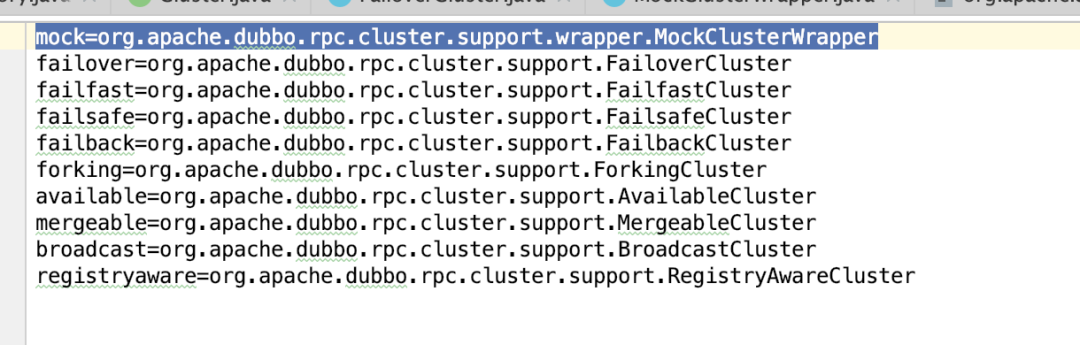
dubbo在Cluster的SPI配置文件中加入了MockClusterWrapper。Dubbo的SPI在加载该配置文件时会解析成的映射,同时将构造方法需要传入一个同类型对象的类视为包装类,不管自适应扩展机制最终获取的是哪个Cluster,都会被包装上注册的所有包装类,而Cluster的SPI配置文件中只注册了MockClusterWrapper这一个包装类。
public class MockClusterWrapper implements Cluster {
private Cluster cluster;
public MockClusterWrapper(Cluster cluster) {
this.cluster = cluster;
}
@Override
public <T> Invoker<T> join(Directory<T> directory) throws RpcException {
return new MockClusterInvoker<T>(directory,
this.cluster.join(directory));
}
}
MockClusterWrapper中创建了MockClusterInvoker,所以MockClusterInvoker以及FailoverClusterInvoker都是在注册中心层包上的。MockClusterInvoker包装了FailoverClusterInvoker。
RPC层DubboProtocol的refer方法是由注册中心层RegistryDirectory调用的,在RegistryDirectory订阅到服务提供者时,根据提供者的数量循环遍历调用。而DubboInvoker在RPC层DubboProtocol创建的,并且也是在RPC层封装为AsyncToSyncInvoker的。所以RegistryDirectory完成将AsyncToSyncInvoker包装为InvokerDelegate,也就是图中的InvokerWrapper。
private Map<String, Invoker<T>> toInvokers(List<URL> urls) {
Map<String, Invoker<T>> newUrlInvokerMap = new HashMap<>();
String queryProtocols = this.queryMap.get(PROTOCOL_KEY);
// 循环遍历所有提供者
for (URL providerUrl : urls) {
URL url = mergeUrl(providerUrl);
......
Map<String, Invoker<T>> localUrlInvokerMap = this.urlInvokerMap; // local reference
Invoker<T> invoker = localUrlInvokerMap == null ? null : localUrlInvokerMap.get(key);
if (invoker == null) {
// 这里创建InvokerDelegate(InvokerWrapper)
invoker = new InvokerDelegate<>(protocol.refer(serviceType, url), url, providerUrl);
newUrlInvokerMap.put(key, invoker);
}else{
newUrlInvokerMap.put(key, invoker);
}
}
return newUrlInvokerMap;
}
所以知道了Invoker的包装链路,顺着这个链路也就能知道整个调用过程了。
负载均衡是何时起作用的?
当cluster配置或默认使用FailoverCluster时,FailoverCluster的join方法创建的就是FailoverClusterInvoker,而负载均衡的调用入口就在FailoverClusterInvoker的doInvoke方法中。因为FailoverClusterInvoker持有RegistryDirectory的引用,所以FailoverClusterInvoker能够获取到服务的所有提供者,自然负责从所有提供者中选择一个调用,这也是集群层要做的事情。
public Result doInvoke(Invocation invocation, final List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
// 调用select方法,传入负载均衡器,从多个服务提供者中选择一个调用
Invoker<T> invoker = select(loadbalance, invocation, copyInvokers, invoked);
Result result = invoker.invoke(invocation);
}
select方法中的第一个参数就是负载均衡器,而loadbalance是doInvoke的参数,所以要看是从哪里传递过来的。这就要看FailoverClusterInvoker的父类的invoke方法。
@Override
public Result invoke(final Invocation invocation) throws RpcException {
.......
List<Invoker<T>> invokers = list(invocation);
// 初始化负载均衡器
LoadBalance loadbalance = initLoadBalance(invokers, invocation);
RpcUtils.attachInvocationIdIfAsync(getUrl(), invocation);
return doInvoke(invocation, invokers, loadbalance);
}
initLoadBalance方法就是从所有可调用的Invoker中取第一个,然后通过SPI自适应扩展点机制从Invoker中获取URL,并从URL中获取负载均衡的参数配置,最后获取到负载均衡器。关于负载均衡的一些介绍可看下往期的两篇文章:《源码分析Dubbo负载均衡策略的权重如何动态修改》、《Dubbo自适应随机负载均衡策略的实现》。
声明:公众号、CSDN、掘金的曾用名:“Java艺术”,因此您可能看到一些早期的文章的图片有“Java艺术”的水印。
![]()
今天我们来分析下`netty`是如何解析`http`协议数据包的。重点是分析`HttpObjectDecoder`类的`decode`方法的源码,`http`协议数据包的解码操作都是在该方法中完成的。
在前面分析Dubbo注册中心层源码的文章中,我们知道,服务的导出与引入由RegistryProtocol调度完成。对于服务提供者,服务是先导出再注册到注册中心;对于服务消费者,先将自己注册到注册中心,再订阅事件,由RegistryDirectory将所有服务提供者转为Invoker。
由于我在实际项目中并未使用Redis作为服务注册中心,所以一直没有关注这个话题。那么,使用Redis作为服务注册中心有哪些缺点,希望本篇文章能给你答案。
服务注册与发现是Dubbo核心的一个模块,假如没有注册中心,我们要调用远程服务,就必须要预先配置,就像调用第三方http接口一样,需要知道接口的域名或者IP、端口号才能调用。
缓存雪崩如何解决?缓存穿透如何解决?如何确保Redis缓存的都是热点数据?如何更新缓存数据?如何处理请求倾斜?实际业务场景下,如何选择缓存数据结构。
订阅
订阅新文章发布通知吧,不错过精彩内容!
输入邮箱,提交后我们会给您发送一封邮件,您需点击邮件中的链接完成订阅设置。