![]()
 云原生实战笔记 专栏收录该内容,点击查看专栏更多内容
云原生实战笔记 专栏收录该内容,点击查看专栏更多内容原创 吴就业 322 0 2024-03-26
本文为博主原创文章,未经博主允许不得转载。
本文链接:https://wujiuye.com/article/8f7347de2360424188fee2a135f29e5b
作者:吴就业
链接:https://wujiuye.com/article/8f7347de2360424188fee2a135f29e5b
来源:吴就业的网络日记
本文为博主原创文章,未经博主允许不得转载。
本篇内容包括:
k8s内置的HPA和VPA使用Metrics API获取指标实现水平和垂直自动扩缩容。但收集指标数据,不适合使用Metrics API,这是来自Metrics Server项目的readme.md的警告:
Metrics Server不适用于非自动缩放目的,即HPA。例如,请勿将其用于将指标转发到监控解决方案,或作为监控解决方案指标的来源。在这种情况下,请直接从 Kubelet 端点收集指标
/metrics/resource。
根据这个提示,如果我们可以直接从Kubelet获取一手的指标数据,就没有必要去获取二手的指标数据,因为二手的指标数据可能并没有那么准确。
通过在每个Node上部署一个DaemonSet Pod,请求节点上的kubelet api :/metrics/resource定时查询指标。
验证:找一个Pod,运行 /bin/sh (或/bin/bash)进入容器终端,并使用curl调用接口:
curl http://<节点的内网IP>:10255/metrics/resource
关于端口号,参考这篇文章:【 Kubelet API - Authentication and Querying - Read-Only Port】
验证输出如下:
~ $ curl http://192.168.0.5:10255/metrics/resource
# HELP container_cpu_usage_seconds_total [ALPHA] Cumulative cpu time consumed by the container in core-seconds
# TYPE container_cpu_usage_seconds_total counter
container_cpu_usage_seconds_total{container="cilium-agent",namespace="kube-system",pod="anetd-g27zk"} 24860.59723 1710838803972
container_cpu_usage_seconds_total{container="cilium-agent-metrics-collector",namespace="kube-system",pod="anetd-g27zk"} 2982.908634 1710838806987
container_cpu_usage_seconds_total{container="csi-driver-registrar",namespace="kube-system",pod="pdcsi-node-cfrbm"} 25406.442824 1710838817443
container_cpu_usage_seconds_total{container="curl-container",namespace="default",pod="curl-daemonset-dn9sd"} 0.052215 1710838796174
container_cpu_usage_seconds_total{container="gce-pd-driver",namespace="kube-system",pod="pdcsi-node-cfrbm"} 164.993794 1710838800991
container_cpu_usage_seconds_total{container="konnectivity-agent",namespace="kube-system",pod="konnectivity-agent-75cc7bdd5c-p8z2q"} 1827.872167 1710838804268
container_cpu_usage_seconds_total{container="metrics-server",namespace="kube-system",pod="metrics-server-v0.5.2-5955b8c8f7-2rmlr"} 14804.891339 1710838809181
container_cpu_usage_seconds_total{container="metrics-server-nanny",namespace="kube-system",pod="metrics-server-v0.5.2-5955b8c8f7-2rmlr"} 54999.795359 1710838812461
container_cpu_usage_seconds_total{container="netd",namespace="kube-system",pod="netd-d5cv2"} 1364.81547 1710838814686
# HELP container_memory_working_set_bytes [ALPHA] Current working set of the container in bytes
# TYPE container_memory_working_set_bytes gauge
container_memory_working_set_bytes{container="cilium-agent",namespace="kube-system",pod="anetd-g27zk"} 1.79757056e+08 1710838803972
container_memory_working_set_bytes{container="cilium-agent-metrics-collector",namespace="kube-system",pod="anetd-g27zk"} 2.3015424e+07 1710838806987
container_memory_working_set_bytes{container="csi-driver-registrar",namespace="kube-system",pod="pdcsi-node-cfrbm"} 6.836224e+06 1710838817443
container_memory_working_set_bytes{container="curl-container",namespace="default",pod="curl-daemonset-dn9sd"} 802816 1710838796174
container_memory_working_set_bytes{container="gce-pd-driver",namespace="kube-system",pod="pdcsi-node-cfrbm"} 5.644288e+06 1710838800991
container_memory_working_set_bytes{container="konnectivity-agent",namespace="kube-system",pod="konnectivity-agent-75cc7bdd5c-p8z2q"} 8.065024e+06 1710838804268
container_memory_working_set_bytes{container="metrics-server",namespace="kube-system",pod="metrics-server-v0.5.2-5955b8c8f7-2rmlr"} 1.921024e+07 1710838809181
container_memory_working_set_bytes{container="metrics-server-nanny",namespace="kube-system",pod="metrics-server-v0.5.2-5955b8c8f7-2rmlr"} 1.5724544e+07 1710838812461
container_memory_working_set_bytes{container="netd",namespace="kube-system",pod="netd-d5cv2"} 9.547776e+06 1710838814686
# HELP container_start_time_seconds [ALPHA] Start time of the container since unix epoch in seconds
# TYPE container_start_time_seconds gauge
container_start_time_seconds{container="cilium-agent",namespace="kube-system",pod="anetd-g27zk"} 1.7055599472026572e+09 1705559947202
container_start_time_seconds{container="cilium-agent-metrics-collector",namespace="kube-system",pod="anetd-g27zk"} 1.7055599478883257e+09 1705559947888
container_start_time_seconds{container="csi-driver-registrar",namespace="kube-system",pod="pdcsi-node-cfrbm"} 1.7055599448828962e+09 1705559944882
container_start_time_seconds{container="curl-container",namespace="default",pod="curl-daemonset-dn9sd"} 1.7108386638098328e+09 1710838663809
container_start_time_seconds{container="gce-pd-driver",namespace="kube-system",pod="pdcsi-node-cfrbm"} 1.705559949653374e+09 1705559949653
container_start_time_seconds{container="konnectivity-agent",namespace="kube-system",pod="konnectivity-agent-75cc7bdd5c-p8z2q"} 1.706085206089776e+09 1706085206089
container_start_time_seconds{container="metrics-server",namespace="kube-system",pod="metrics-server-v0.5.2-5955b8c8f7-2rmlr"} 1.7061716154364083e+09 1706171615436
container_start_time_seconds{container="metrics-server-nanny",namespace="kube-system",pod="metrics-server-v0.5.2-5955b8c8f7-2rmlr"} 1.706171616291431e+09 1706171616291
container_start_time_seconds{container="netd",namespace="kube-system",pod="netd-d5cv2"} 1.7055599563002608e+09 1705559956300
# HELP node_cpu_usage_seconds_total [ALPHA] Cumulative cpu time consumed by the node in core-seconds
# TYPE node_cpu_usage_seconds_total counter
node_cpu_usage_seconds_total 440394.065629 1710838808088
# HELP node_memory_working_set_bytes [ALPHA] Current working set of the node in bytes
# TYPE node_memory_working_set_bytes gauge
node_memory_working_set_bytes 1.23457536e+09 1710838808088
# HELP pod_cpu_usage_seconds_total [ALPHA] Cumulative cpu time consumed by the pod in core-seconds
# TYPE pod_cpu_usage_seconds_total counter
pod_cpu_usage_seconds_total{namespace="default",pod="curl-daemonset-dn9sd"} 0.110845 1710838809083
pod_cpu_usage_seconds_total{namespace="kube-system",pod="anetd-g27zk"} 27843.802109 1710838806009
pod_cpu_usage_seconds_total{namespace="kube-system",pod="konnectivity-agent-75cc7bdd5c-p8z2q"} 1827.92195 1710838808605
pod_cpu_usage_seconds_total{namespace="kube-system",pod="metrics-server-v0.5.2-5955b8c8f7-2rmlr"} 69804.745235 1710838813516
pod_cpu_usage_seconds_total{namespace="kube-system",pod="netd-d5cv2"} 1365.237171 1710838810745
pod_cpu_usage_seconds_total{namespace="kube-system",pod="pdcsi-node-cfrbm"} 25571.405191 1710838808497
# HELP pod_memory_working_set_bytes [ALPHA] Current working set of the pod in bytes
# TYPE pod_memory_working_set_bytes gauge
pod_memory_working_set_bytes{namespace="default",pod="curl-daemonset-dn9sd"} 1.073152e+06 1710838809083
pod_memory_working_set_bytes{namespace="kube-system",pod="anetd-g27zk"} 2.03657216e+08 1710838806009
pod_memory_working_set_bytes{namespace="kube-system",pod="konnectivity-agent-75cc7bdd5c-p8z2q"} 8.2944e+06 1710838808605
pod_memory_working_set_bytes{namespace="kube-system",pod="metrics-server-v0.5.2-5955b8c8f7-2rmlr"} 3.5336192e+07 1710838813516
pod_memory_working_set_bytes{namespace="kube-system",pod="netd-d5cv2"} 1.0018816e+07 1710838810745
pod_memory_working_set_bytes{namespace="kube-system",pod="pdcsi-node-cfrbm"} 1.284096e+07 1710838808497
# HELP scrape_error [ALPHA] 1 if there was an error while getting container metrics, 0 otherwise
# TYPE scrape_error gauge
scrape_error 0
由于/metrics/resource并不直接给出cpu使用率,而是给出cpu使用时间pod_cpu_usage_seconds_total。CPU使用率需要通过公式计算:CPU使用时间 / CPU总时间 = CPU使用率。
但这应该是在需要换算成使用率的时候再计算,因为指标的值是累加的。
我们以计算node的cpu使用率为例,验证公式是否准确。(因为kubectl top nodes命令可以查看node的cpu使用率)
发送两次curl请求取node_cpu_usage_seconds_total指标,并记录下来。
node_cpu_usage_seconds_total 440622.88009 1710842537802
node_cpu_usage_seconds_total 440624.781901 1710842567875
node_cpu_usage_seconds_total后面有两个数字:一个是使用时间,单位核心/秒;一个是时间戳,单位毫秒。单位不一样,所以需要换算一下,所示计算公式是:
(440624.781901 - 440622.88009) / ((1710842567875 - 1710842537802) / 1000)
= 1.901811 / 30.073
= 0.06324
= 6.324%
使用kubectl top nodes命令查看该节点的使用率也刚好是6%。

通过使用官方提供的grafana agent docker镜像,编写一个DaemonSet实现在每个Node上部署一个grafana agent收集指标并上报。
DaemonSet如下:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: grafana-agent
spec:
selector:
matchLabels:
app: grafana-agent
template:
metadata:
labels:
app: grafana-agent
spec:
containers:
- name: grafana-agent
image: grafana/agent:latest
command:
- grafana-agent
- -config.file=/etc/agent/agent.yaml
- -metrics.wal-directory=/tmp/metrics
- -config.expand-env # 使环境变量能够替换配置文件中的占位符'${xxx}'
env:
- name: METRICS_PORT
value: '10255'
- name: NODE_INTRANET_IP
valueFrom:
fieldRef:
fieldPath: status.hostIP
volumeMounts:
- name: config-volume
mountPath: /etc/agent
volumes:
- name: config-volume
configMap:
name: grafana-agent-config
其中command的-config.expand-env参数用来启用配置文件支持环境变量注入。后续会说到。
config-volume卷:我们将grafana agent的配置文件写成一个configmap,然后将configmap挂到Pod上。这里就是将grafana-agent-config这个configmap挂到容器的/etc/agent目录,然后grafana-agent-config有个key是agent.yaml,所以最终会在Pod生成/etc/agent/agent.yaml这个配置文件。所以command需要指定这个配置文件:-config.file=/etc/agent/agent.yaml。
环境变量:
配置文件内容:
apiVersion: v1
kind: ConfigMap
metadata:
name: grafana-agent-config
data:
agent.yaml: |
server:
log_level: debug
metrics:
global:
scrape_interval: 1m
configs:
- name: agent
scrape_configs:
- job_name: kubelet-metrics-resource
metrics_path: /metrics/resource
static_configs:
- targets:
- "${NODE_INTRANET_IP}:${METRICS_PORT}"
remote_write:
- url: https://prometheus-prod-13-prod-us-east-0.grafana.net/api/prom/push
basic_auth:
username: '1491097'
password: 'xxxxxxxxxx'
配置项说明:
global.scrape_interval:指标上报的间隔,1m为1分钟。metrics_path:采集指标的接口。static_configs.targets:采集目标,这里用到了${VAR}环境变量,${NODE_INTRANET_IP}和${METRICS_PORT}这两个占位符会被我们设置的环境变量替换。remote_write:配置指标上传接口,将指标上传到prometheus。basic_auth为接口授权配置。我们是使用的Grafana Cloud提供的Prometheus产品。
假如你已经注册了Grafana Cloud,有一个Grafana Cloud的账号。
现在可以进入My Account页面,然后找到Prometheus产品,点击Details按钮。
在Prometheus产品实例页面,找到Sending metrics。
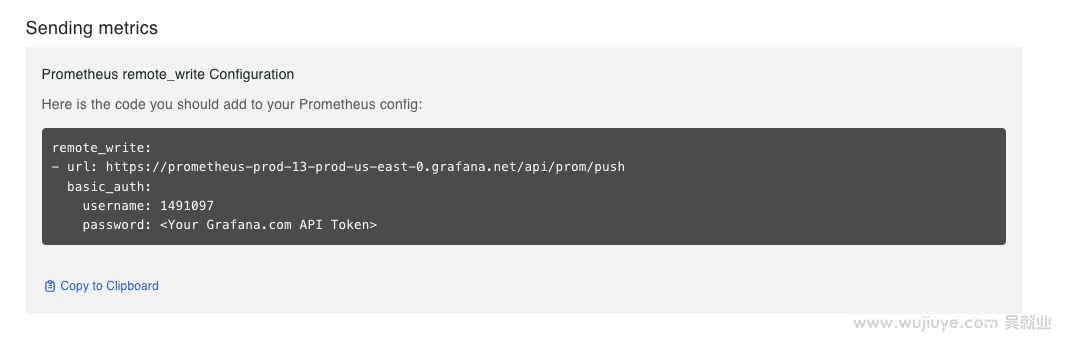
Sending metrics就直接给出了remote_write的配置。然后我们在页面上找到Password/API Token,点击Generate now生产一个密码,这个密码替换basic_auth.password。

最后,如何查看收集的指标?
在Prometheus产品实例页面,找到Using a self-hosted Grafana instance with Grafana Cloud Metrics。
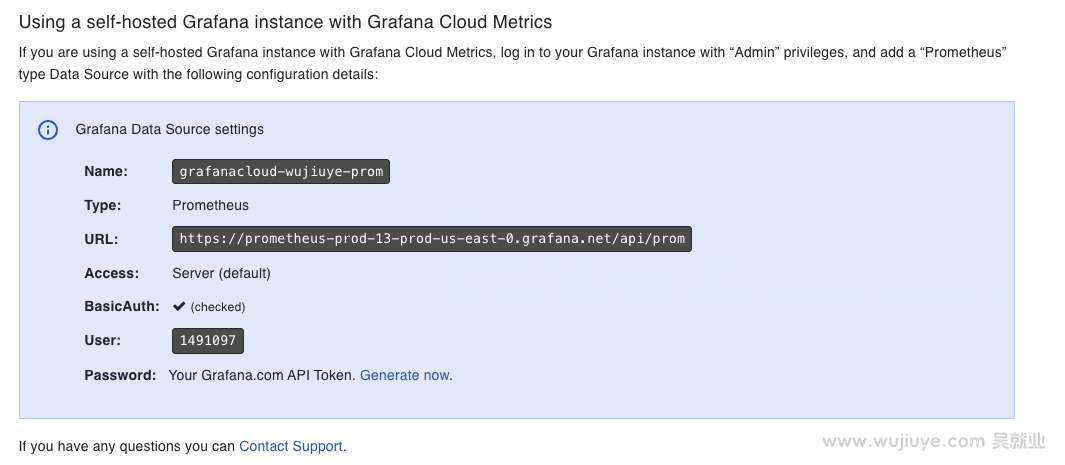
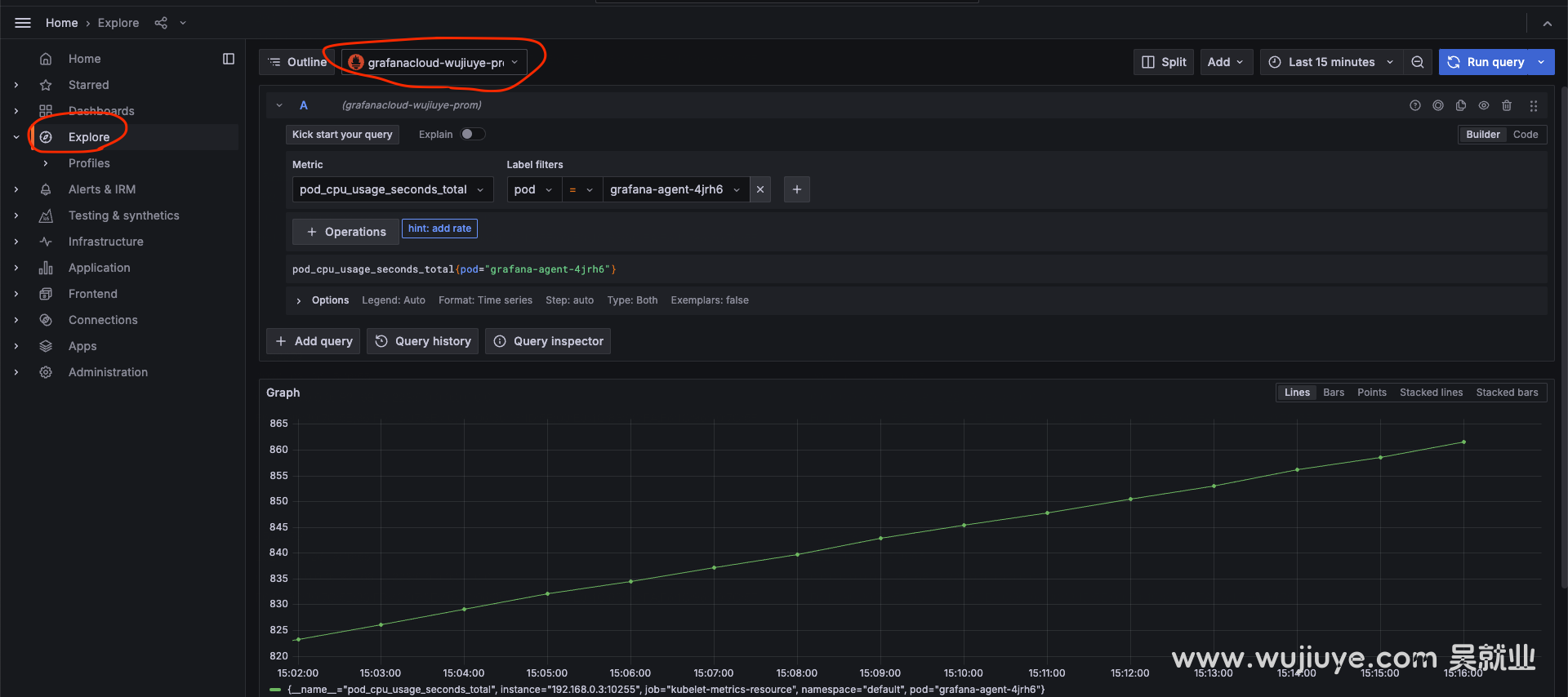
这里可以看到我们的数据源名称。这里是grafanacloud-wujiuye-prom。
回到My Account页面,然乎找到Grafana产品,点击Launch按钮进入Grafana控制台。
点击explore菜单,数据源选择grafanacloud-wujiuye-prom。然后就可以查看收集的指标了。
参考文献:
声明:公众号、CSDN、掘金的曾用名:“Java艺术”,因此您可能看到一些早期的文章的图片有“Java艺术”的水印。
![]()
前面《如何获取Pod的CPU和内存指标,使用Grafana Agent收集指标,上传到Prometheus》这篇介绍的指标获取只拿到了cpu使用率,怎么转成cpu使用量呢?
通常指标和日志收集这两者是一起的,可观测即离不开指标,也离不开日记。当两者都需要的时候,就没必要部署两个DaemonSet了。本篇将两者结合成一个完整的案例,大家可以直接拿去部署使用。
本篇是作者在云原生PaaS平台项目中实战可观测能力做的技术调研,将关键技术知识点讲透,涉及:如何获取Pod的标准输出(stdout)日志、如何使用Grafana Agent收集日志(附配置案例讲解)、如何将日志上传Grafana Loki。
不禁感叹,k8s这个底座设计的太牛了,我们不仅可以通过CRD + 控制器做扩展,还可以自定义APIService去做扩展。k8s,牛啊!
订阅
订阅新文章发布通知吧,不错过精彩内容!
输入邮箱,提交后我们会给您发送一封邮件,您需点击邮件中的链接完成订阅设置。