![]()
 深入理解Sentinel 专栏收录该内容,点击查看专栏更多内容
深入理解Sentinel 专栏收录该内容,点击查看专栏更多内容原创 吴就业 200 0 2020-09-22
本文为博主原创文章,未经博主允许不得转载。
本文链接:https://wujiuye.com/article/499545831f19400bb2fdb4dc003fc8df
作者:吴就业
链接:https://wujiuye.com/article/499545831f19400bb2fdb4dc003fc8df
来源:吴就业的网络日记
本文为博主原创文章,未经博主允许不得转载。
笔者想跟大家分享笔者经历的一次服务雪崩事故,分析导致此次服务雪崩事故的原因。或许大多数读者都有过这样的经历,这是项目给我们上的一次非常宝贵的实战课程。
什么是服务雪崩?雪崩一词指的是山地积雪由于底部溶解等原因而突然大块塌落的现象,具有很强的破坏力,在微服务项目中指由于突发流量导致某个服务不可用,从而导致上游服务不可用,并产生级联效应,最终导致整个系统不可用,使用雪崩这个词来形容这一现象最合适不过。
服务雪崩,听到这个词就能想到问题的严重性。是的,当时公司整条业务线的服务都挂了,从该业务线延伸出来的下游业务线也被波及。笔者当时是连续三天两夜的忙着处理问题,加起来睡眠时间不足5小时,正是如此,印象非常深刻。
其实这一天的到来我是有预感的,但我以为会是数据量上升导致,实际却是并发量先上升,而严重程度超出我的预料。问题出现那天,我们还在进行每周的技术分享会,结果一运营小姐姐推开会议室的大门传来噩耗,画面瞬间转变,技术分享会变成了问题排查讨论会。
当时看了服务的负载均衡统计,发现并发请求量增长了一倍,从每分钟3到4万的请求数,增长到8.6万。在事发之前,服务一直稳定运行,很显然,这次事故与并发量翻倍有直接的关系。
这是由笔者负责技术选型与架构设计的一个分布式广告系统,也是笔者入门分布式微服务实战的第一个项目,从设计到实现,期间遇到过很多的难题,被项目推着走,熬了很多个夜,但也颇有收获。
关于服务的部署:
从当时查看服务打印的日记可以看出三个问题:
我们配置服务B每个接口的超时时间都是3秒。服务B提供的接口的实现都是缓存级别的操作,3秒的超时时间,理论上除了网络问题,调用不可能会超过这个值。
服务B每个节点配置了200个最小连接数的Jedis连接池,这是根据Netty工作线程数配置的,即读写操作就算200个线程并发执行,也能为每个线程分配一个Jedis连接。
SocketChannel套接字会占用一个文件句柄,有多少个客户端连接就占用多少个文件句柄。我们在服务的启动脚本上为每个进程配置102400的最大文件打开数,理论上当时的并发量并不可能会达到这个数值。服务A底层用的是自研的基于Netty实现的http服务框架,没有限制最大连接数。
所以,这三个问题就是排查此次服务雪崩真正原因的突破口。
首先是怀疑Redis服务扛不住这么大的并发请求。根据业务代码估算,处理广告的一次点击需要执行30次get操作从redis获取数据,那么每分钟8w并发,就需要执行240w次get请求,而redis除了本文提到的服务A和服务B用到外,还有其它两个并发量高的服务在用,保守估计,redis每分钟需要承受300w的读写请求。转为每秒就是5w的读写请求,与理论值Redis每秒可以处理超过 10万次读写操作已经过半。
由于历史原因,Redis使用的还是2.x的版本,用的一主一从,Jedis配置连接池是读写分离的连接池,也就是写请求打到主节点,读请求打到从节点。由于写请求非常的少,大多都是定时15分钟写一次,因此可先忽略写请求对Redis性能的影响,那么就是每秒接近5w读请求只有一个Redis从节点处理。所以我们将Redis升级到4.x版本,并由主从集群改为分布式集群,两主无从(使用AWS的Redis服务可以配置无从节点,还是节约成本的问题)。
Redis升级后,理论上,两个主节点分槽位后请求会平摊到两个节点上,性能应该会好很多。但好景不长,服务重新上线一个小时不到,并发又突增到了六七万每分钟,这次是大量的RPC远程调用超时,已经没有Jedis的读超时(Read time out)了,相比之前好了点,至少不用再给Redis加节点,排除掉Redis性能瓶颈。
虽然升级后没有Read time out! 但某个Jedis的Get读操作还是很耗时,这才是罪魁祸首。Redis的命令耗时与Jedis的读操作Read time out不同,Jedis的读操作还受网络传输的影响,Redis响应的数据包越大,Jedis接收数据包就越耗时。Redis执行一条命令的过程分为:
Jedis的get耗时长导致服务B接口执行耗时超过设置的3s。服务A向服务B发起RPC调用,虽然dubbo消费端超时放弃请求,但是请求已经发出,就算消费端取消,提供者无法感知服务A超时放弃了,没有中断当前正在执行的线程,所以服务B还是要执行完一次调用的业务逻辑,这与说出去的话收不回来一样的道理。
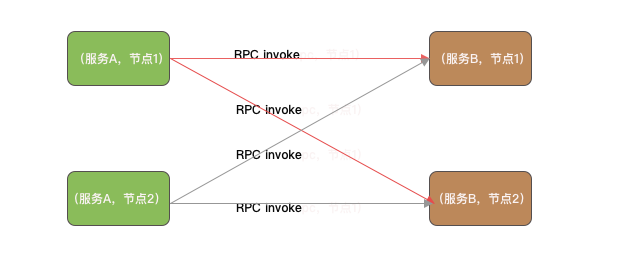
Dubbo集群容错机制默认使用Failover,即当调用出现失败时,重试其它服务节点。默认会重试两次,不算第一个调用,所以最坏情况下,一共会发起三次RPC调用,如下图所示。
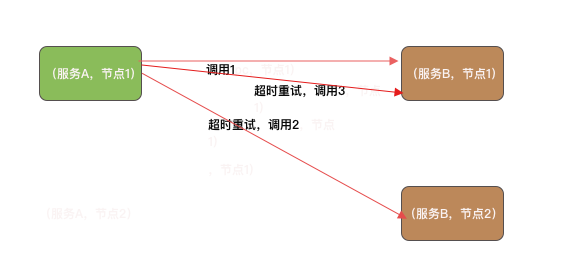
当服务A超时放弃时,Dubbo的集群容错处理会重新选择服务B的一个节点发起调用,所以并发8w对于服务B而言,最糟糕的情况下就变成了并发24w。最后导致服务B的每个节点业务线程池的线程一直被占用,RPC远程调用又多出了一个异常,就是远程服务线程池已满,服务B直接响应失败。
问题最终还是要回到Jedis的Read time out上,就是key对应的value太大导致传输耗时,业务代码拿到value后将value分割成数组,判断请求参数是否在数组中也非常耗时,就会导致服务B处理接口调用耗时超过3s,从而导致服务B不可用,服务B不可用直接拖垮服务A。
模拟服务B接口的业务代码如下:
public class Match {
static class Task implements Runnable {
private String value;
public Task(String value) {
this.value = value;
}
@Override
public void run() {
for (; ; ) {
// 模拟jedis get耗时
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
// =====> 实际业务代码
long start = System.currentTimeMillis();
List<String> ids = Arrays.stream(value.split(",")).collect(Collectors.toList());
// 判断字符串是否存在数组中
boolean exist = ids.contains("4029000");
// ====> 输出业务代码耗时.
System.out.println("exist:" + exist + ",time:" + (System.currentTimeMillis() - start));
}
}
};
public static void main(String[] args) {
// 模拟业务场景,从缓存中获取到的字符串
StringBuilder value = new StringBuilder();
for (int i = 4000000; i <= 4029000; i++) {
value.append(String.valueOf(i)).append(",");
}
String strValue = value.toString();
System.out.println(strValue.length());
// 开启200个线程执行Task的run方法
for (int i = 0; i < 200; i++) {
new Thread(new Task(strValue)).start();
}
}
}
这段代码很简单,就是模拟高并发,观察在200个业务线程全部耗尽的情况下,一个简单的判断元素是否存在的业务逻辑执行需要多长时间。把这段代码跑一遍,发现很多执行耗时超过1500ms,如下图所示。
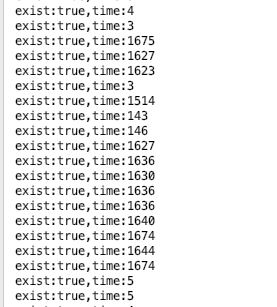
缓存的value字符串越长,这段代码就越耗时,同时也越消耗内存。如果再加上Jedis从发送get请求到接收完成Redis响应的数据包的耗时,接口的执行总耗时就会超过3000ms。所以,导致服务雪崩的根本原因就是这个隐藏的性能问题。
代码层面的优化就是将id拼接成字符串的存储方式改为使用hash结构存储,直接hget方式判断一个元素是否存在,不需要将这么大的数据读取到本地,即避免了网络传输消耗,也优化了接口的执行速度。当然,最好使用bitmap存储,但由于该缓存还有其它用途,因此才选用hash。
造成这次服务雪崩事故的原因分析总结:
服务B的奔溃导致服务A奔溃,正是这种级联效应导致服务雪崩。
另外,由定时任务服务调用服务B的接口,在每次任务执行时,都会导致服务B变得不可用。由于是内部服务,我们可以通过修改定时任务发送请求的线程数和频率来降低接口的QPS,一开始我们也是这么做的。但如果有其它第三方的定时任务服务调用这个接口就不好控制了。
为避免流量再次突增导致服务雪崩,在优化完业务代码和缓存设计后,我们也为项目引入了断路器:Sentinel,为接口配置熔断降级规则、系统负载保护规则,当服务器负载过高或者请求失败率过高时,自动熔断上游服务的请求,以确保服务能够稳定运行。由于Sentinel支持按来源限流,我们也为定时任务发起的请求配置限流规则,限制服务B同时只能有五个线程处理定时任务发起的请求。
Sentinel是阿里于2018年开源的微服务断路器组件,意义为流量防卫兵,承接了阿里巴巴近10 年的双十一大促流量的核心场景,目前已有13.3k的Star。Sentinel以流量为切入点,实现流量控制、熔断降级、系统负载保护等多种服务降级方式保护服务的稳定性,并已提供对多种主流框架的适配,例如Spring Cloud、Dubbo。
之所以在学习Sentinel之前跟大家分享这个服务雪崩故事,是想通过这次事故帮助读者更好的理解什么是服务雪崩。这次服务雪崩事故,让笔者明白了服务降级在分布式系统中的重要性。可以这么说,微服务项目不能缺少服务降级,每个服务都需要有自我保护的能力。
深入了解Sentinel将有助于我们更好的使用Sentinel提供的特性,并可对其实现扩展以满足我们的需求。了解Sentinel首先是要攻克其基于滑动窗口实现的指标数据统计、以及基于责任链模式实现的服务降级过滤器链,在掌握这两点之后,整个Sentinel的框架源码将不难理解。Sentinel实现的冷启动限流效果算法与匀速限流效果的算法算是限流模块中最难理解的一部份,在介绍这部分内容时会结合Guava的限流算法分析,降低理解难度。
本专栏内容安排如下:
关于源码分析,笔者选择的是Sentinel 1.7.1版本。
笔者想要研究Sentinel的源码一开始只是好奇Sentinel是怎么统计每个接口的QPS的,并且也模仿Sentinel实现了一个基于滑动窗口的QPS统计工具,但后来又不满足于这搁浅的认识,于是深入探索Sentinel整个框架的核心实现原理,在对Sentinel有一定的了解后,也基于Sentinel做过一些扩展,例如,笔者在最近的一个新项目中,在网关层实现请求的熔断(项目从单体迁移的一些原因)、抛弃aop+redis实现开关降级的方式,基于Sentinel实现开关降级提高了开关降级的灵活度。
笔者第一次看Sentinel源码也感觉无从下手,特别是关于节点树这些概念的理解,也是硬着头片去啃源码,结合官方文档去揣摩代码背后的设计思想。基于Sentinel自学难度高、分析Sentinel原理细节的资料零零散散且不全、官方文档介绍得不够深入,笔者下定决心完成此专栏,希望能够帮助到想要深入学习了解Sentinel的读者。由于笔者的表达能力有限,如果有表达不够清晰或者表达错误的地方,还恳请大家帮忙指出。
声明:公众号、CSDN、掘金的曾用名:“Java艺术”,因此您可能看到一些早期的文章的图片有“Java艺术”的水印。
![]()
本篇内容介绍如何使用r2dbc-mysql驱动程序包与mysql数据库建立连接、使用r2dbc-pool获取数据库连接、Spring-Data-R2DBC增删改查API、事务的使用,以及R2DBC Repository。
消息推送服务主要是处理同步给用户推送短信通知或是异步推送短信通知、微信模板消息通知等。本篇介绍如何使用Spring WebFlux + R2DBC搭建消息推送服务。
IDEA有着极强的扩展功能,它提供插件扩展支持,让开发者能够参与到IDEA生态建设中,为更多开发者提供便利、提高开发效率。我们常用的插件有Lombok、Mybatis插件,这些插件都大大提高了我们的开发效率。即便IDEA功能已经很强大,并且也已有很多的插件,但也不可能面面俱到,有时候我们需要自给自足。
Instrumentation之所以难驾驭,在于需要了解Java类加载机制以及字节码,一不小心就能遇到各种陌生的Exception。笔者在实现Java探针时就踩过不少坑,其中一类就是类加载相关的问题,也是本篇所要跟大家分享的。
订阅
订阅新文章发布通知吧,不错过精彩内容!
输入邮箱,提交后我们会给您发送一封邮件,您需点击邮件中的链接完成订阅设置。