![]()
 深入理解Sentinel 专栏收录该内容,点击查看专栏更多内容
深入理解Sentinel 专栏收录该内容,点击查看专栏更多内容原创 吴就业 211 0 2020-09-22
本文为博主原创文章,未经博主允许不得转载。
本文链接:https://wujiuye.com/article/430a24f972bb4a3aa05a8871286fa25e
作者:吴就业
链接:https://wujiuye.com/article/430a24f972bb4a3aa05a8871286fa25e
来源:吴就业的网络日记
本文为博主原创文章,未经博主允许不得转载。
Sentinel是基于滑动窗口实现的实时指标数据统计,要深入理解Sentinel的限流实现原理,首先我们得要了解其指标数据统计的实现,例如,如何统计QPS。
为了简单,我们不直接分析Sentinel的源码,而是分析笔者从Sentinel中摘抄的,且经过改造后的“qps-helper”工具包的代码。总体上是一样的,笔者去掉了一些不需要的指标统计,以及将Sentinel一些自定义的类替换成JDK提供的类,封装成通用的QPS统计工具包。当然,您也可以直接看Sentinel的源码,差别不大,源码在sentinel-core的slots包下。
qps-helper代码下载地址:https://github.com/wujiuye/qps-helper
Sentinel使用Bucket统计一个窗口时间内的各项指标数据,这些指标数据包括请求总数、成功总数、异常总数、总耗时、最小耗时、最大耗时等,而一个Bucket可以是记录一秒内的数据,也可以是10毫秒内的数据,这个时间长度称为窗口时间。qps-helper只统计请求成功总数、请求异常数、总耗时。
public class MetricBucket {
/**
* 存储各事件的计数,比如异常总数、请求总数等
*/
private final LongAdder[] counters;
/**
* 这段事件内的最小耗时
*/
private volatile long minRt;
}
如上面代码所示,Bucket记录一段时间内的各项指标数据用的是一个LongAdder数组,LongAdder保证了数据修改的原子性,并且性能比AtomicInteger表现更好。数组的每个元素分别记录一个时间窗口内的请求总数、异常数、总耗时,如下图所示。
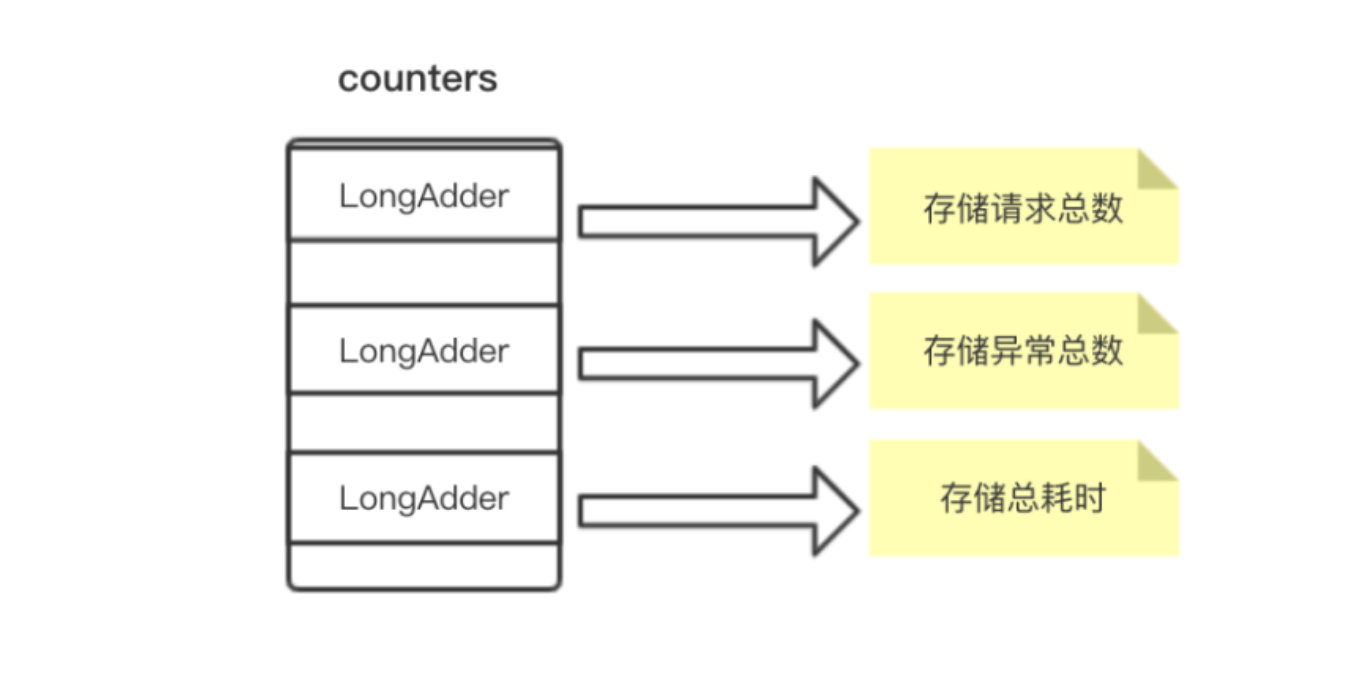
Sentinel用枚举类型MetricEvent的ordinal属性作为下标,ordinal的值从0开始,按枚举元素的顺序递增,正好可以用作数组的下标。在qps-helper中,LongAdder被替换为j.u.c包下的atomic类了,并且只保留EXCEPTION、SUCCESS、RT,代码如下。
// 事件类型
public enum MetricEvent {
EXCEPTION,// 异常 对应数组下标为0
SUCCESS, // 成功 对应数组下标为1
RT // 耗时 对应数组下标为2
}
当需要获取Bucket记录总的成功请求数或者异常总数、总的请求处理耗时,可根据事件类型(MetricEvent)从Bucket的LongAdder数组中获取对应的LongAdder,并调用sum方法获取总数,如下代码所示。
// 假设事件为MetricEvent.SUCCESS
public long get(MetricEvent event) {
// MetricEvent.SUCCESS.ordinal()为1
return counters[event.ordinal()].sum();
}
当需要Bucket记录一个成功请求或者一个异常请求、处理请求的耗时,可根据事件类型(MetricEvent)从LongAdder数组中获取对应的LongAdder,并调用其add方法,如下代码所示。
// 假设事件为MetricEvent.RT
public void add(MetricEvent event, long n) {
// MetricEvent.RT.ordinal()为2
counters[event.ordinal()].add(n);
}
如果我们希望能够知道某个接口的每秒处理成功请求数(成功QPS)、每秒处理失败请求数(失败QPS),以及处理每个成功请求的平均耗时(avg RT),我们只需要控制Bucket统计一秒钟内的指标数据即可。但如何才能确保Bucket存储的就是精确到1秒内的数据呢?
最low的做法就是启一个定时任务每秒创建一个Bucket,但统计出来的数据误差绝对很大。Sentinel是这样实现的,它定义一个Bucket数组,根据时间戳来定位到数组的下标。
假设我们需要统计每1秒处理的请求数等数据,且只需要保存最近一分钟的数据。那么Bucket数组的大小就可以设置为60,每个Bucket的windowLengthInMs(窗口时间)大小就是1000毫秒(1秒),如下图所示。
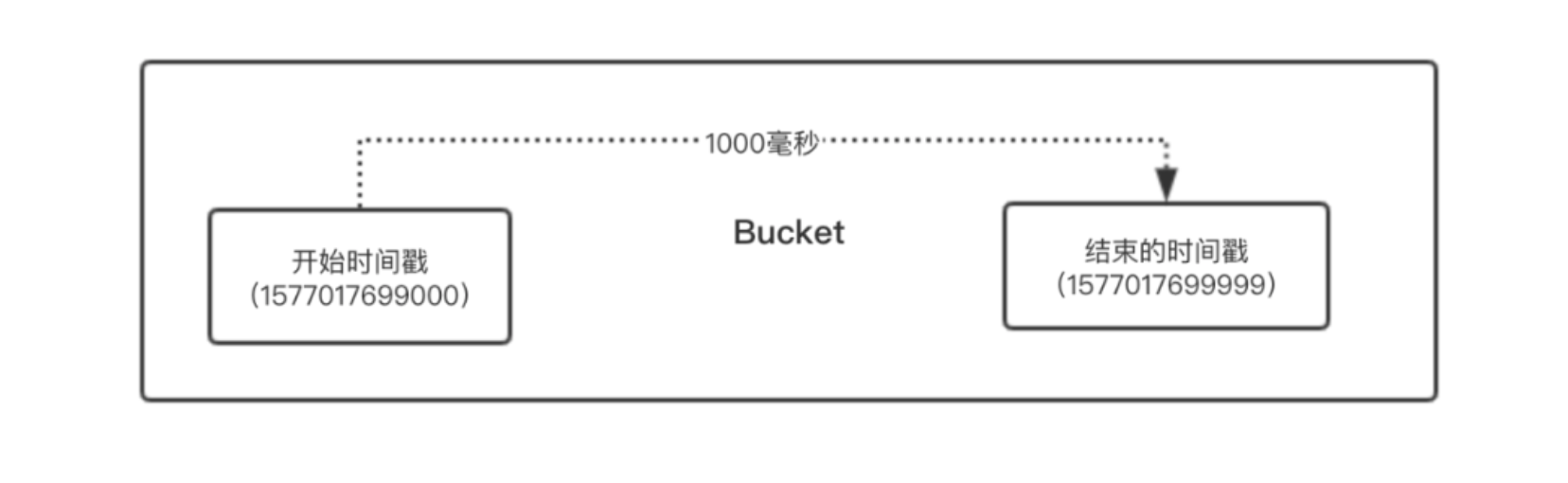
由于每个Bucket存储的是1秒的数据,假设Bucket数组的大小是无限大的,那么我们只需要将当前时间戳去掉毫秒部分就能得到当前的秒数,将得到的秒数作为索引就能从Bucket数组中获取当前时间窗口的Bucket。
一切资源均有限,所以我们不可能无限的存储Bucket,我们也不需要存储那么多历史数据在内存中。当我们只需要保留一分钟的数据时,Bucket数组的大小就可以设置为60,我们希望这个数组可以循环使用,并且永远只保存最近1分钟的数据,这样不仅可以避免频繁的创建Bucket,也减少内存资源的占用。
这种情况下如何定位Bucket呢?我们只需要将当前时间戳去掉毫秒部分得到当前的秒数,再将得到的秒数与数组长度取余数,就能得到当前时间窗口的Bucket在数组中的位置(索引),如下图所示。
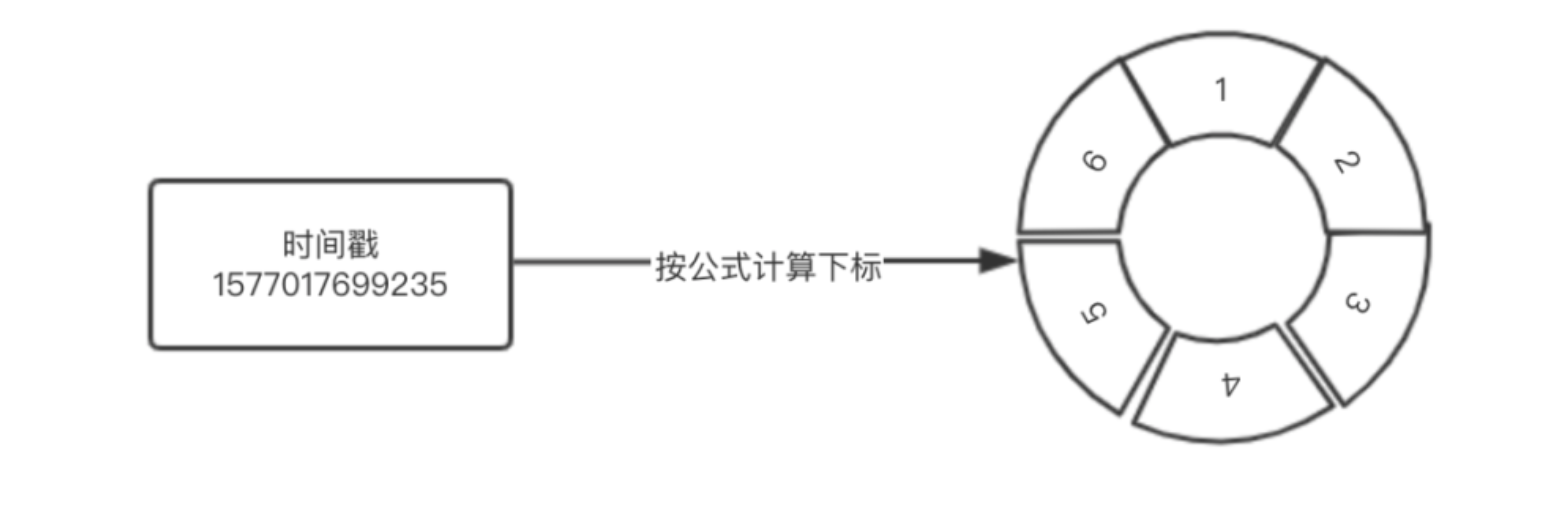
根据当前时间戳计算出当前时间窗口的Bucket在数组中的索引,算法实现如下:
private int calculateTimeIdx(long timeMillis) {
/**
* 假设当前时间戳为1577017699235
* windowLengthInMs为1000毫秒(1秒)
* 则
* 将毫秒转为秒 => 1577017699
* 映射到数组的索引为 => 19
*/
long timeId = timeMillis / windowLengthInMs;
return (int) (timeId % array.length());
}
calculateTimeIdx方法中,取余数就是实现循环利用数组。如果想要获取连续的一分钟的Bucket数据,就不能简单的从头开始遍历数组,而是指定一个开始时间和结束时间, 从开始时间戳开始计算Bucket存放在数组中的下标,然后循环每次将开始时间戳加上1秒,直到开始时间等于结束时间。
由于循环使用的问题,当前时间戳与一分钟之前的时间戳和一分钟之后的时间戳都会映射到数组中的同一个Bucket,因此,必须要能够判断取得的Bucket是否是统计当前时间窗口内的指标数据,这便要数组每个元素都存储Bucket时间窗口的开始时间戳。
比如当前时间戳是1577017699235,Bucket统计一秒的数据,将时间戳的毫秒部分全部替换为0,就能得到Bucket时间窗口的开始时间戳为1577017699000。
计算Bucket时间窗口的开始时间戳代码实现如下。
protected long calculateWindowStart(long timeMillis) {
/**
* 假设窗口大小为1000毫秒,即数组每个元素存储1秒钟的统计数据
* timeMillis % windowLengthInMs 就是取得毫秒部分
* timeMillis - 毫秒数 = 秒部分
* 这就得到每秒的开始时间戳
*/
return timeMillis - timeMillis % windowLengthInMs;
}
因为Bucket自身并不保存时间窗口信息,所以Sentinel给Bucket加了一个包装类WindowWrap,用于记录Bucket的时间窗口信息,WindowWrap源码如下。
public class WindowWrap<T> {
/**
* 窗口时间长度(毫秒)
*/
private final long windowLengthInMs;
/**
* 开始时间戳(毫秒)
*/
private long windowStart;
/**
* 统计数据
*/
private T value;
public WindowWrap(long windowLengthInMs, long windowStart, T value) {
this.windowLengthInMs = windowLengthInMs;
this.windowStart = windowStart;
this.value = value;
}
}
如前面所说,假设Bucket以秒为单位统计指标数据,那么Bucket统计的就是一秒内的请求总数、异常总数这些指标数据。换算为毫秒为单位,比如时间窗口为:[1577017699000 , 1577017699999),那么1577017699000就被称为该时间窗口的开始时间(windowStart)。一秒转为毫秒是1000,所以1000就称为窗口时间大小(windowLengthInMs)。
windowStart + windowLengthInMs = 时间窗口的结束时间
只要知道时间窗口的开始时间和窗口时间大小,只需要给定一个时间戳,就能知道该时间戳是否在Bucket的窗口时间内,代码实现如下。
/**
* 检查给定的时间戳是否在当前bucket中。
*
* @param timeMillis 时间戳,毫秒
* @return
*/
public boolean isTimeInWindow(long timeMillis) {
return windowStart <= timeMillis && timeMillis < windowStart + windowLengthInMs;
}
Bucket用于统计各项指标数据,WindowWrap用于记录Bucket的时间窗口信息,记录窗口的开始时间和窗口的大小,WindowWrap数组就是一个滑动窗口。
当接收到一个请求时,可根据接收到请求的时间戳计算出一个数组索引,从滑动窗口(WindowWrap数组)中获取一个WindowWrap,从而获取WindowWrap包装的Bucket,调用Bucket的add方法记录相应的事件。
根据当前时间戳定位Bucket的算法实现如下。
/**
* 根据时间戳获取bucket
*
* @param timeMillis 时间戳(毫秒)
* @return 如果时间有效,则在提供的时间戳处显示当前存储桶项;如果时间无效,则为空
*/
public WindowWrap<T> currentWindow(long timeMillis) {
if (timeMillis < 0) {
return null;
}
// 获取时间戳映射到的数组索引
int idx = calculateTimeIdx(timeMillis);
// 计算bucket时间窗口的开始时间
long windowStart = calculateWindowStart(timeMillis);
// 从数组中获取bucket
while (true) {
WindowWrap<T> old = array.get(idx);
// 一般是项目启动时,时间未到达一个周期,数组还没有存储满,没有到复用阶段,所以数组元素可能为空
if (old == null) {
// 创建新的bucket,并创建一个bucket包装器
WindowWrap<T> window = new WindowWrap<T>(windowLengthInMs, windowStart, newEmptyBucket(timeMillis));
// cas写入,确保线程安全,期望数组下标的元素是空的,否则就不写入,而是复用
if (array.compareAndSet(idx, null, window)) {
return window;
} else {
Thread.yield();
}
}
// 如果WindowWrap的windowStart正好是当前时间戳计算出的时间窗口的开始时间,则就是我们想要的bucket
else if (windowStart == old.windowStart()) {
return old;
}
// 复用旧的bucket
else if (windowStart > old.windowStart()) {
if (updateLock.tryLock()) {
try {
// 重置bucket,并指定bucket的新时间窗口的开始时间
return resetWindowTo(old, windowStart);
} finally {
updateLock.unlock();
}
} else {
Thread.yield();
}
}
// 计算出来的当前bucket时间窗口的开始时间比数组当前存储的bucket的时间窗口开始时间还小,
// 直接返回一个空的bucket就行
else if (windowStart < old.windowStart()) {
return new WindowWrap<T>(windowLengthInMs, windowStart, newEmptyBucket(timeMillis));
}
}
}
上面代码实现的是,通过当前时间戳计算出当前时间窗口的Bucket(New Buket)在数组中的索引(cidx),以及Bucket时间窗口的开始时间,通过索引从数组中取得Bucket(Old Bucket)。
根据当前时间戳计算出当前Bucket的时间窗口开始时间,用当前Bucket的时间窗口开始时间减去一个窗口时间大小就能定位出前一个Bucket。
由于是使用数组实现滑动窗口,数组的每个元素都会被循环使用,因此当前Bucket与前一个Bucket会有相差一个完整的滑动窗口周期的可能,如下图所示。
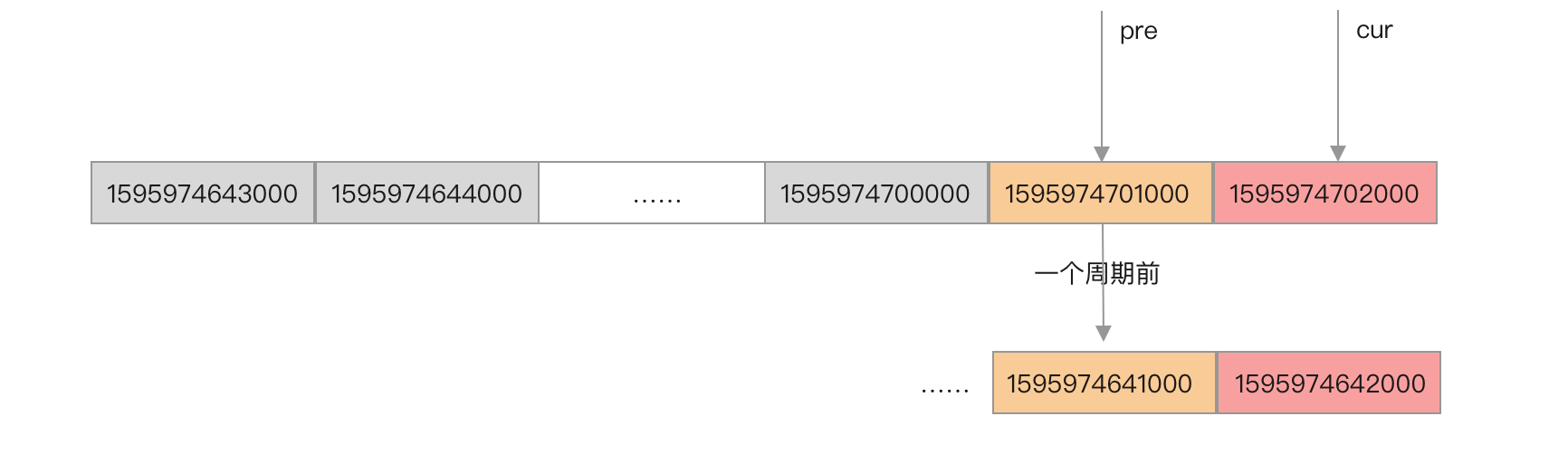
当前时间戳对应的Bucket的时间窗口开始时间戳为1595974702000,而前一个Bucket的时间窗口开始时间戳可能是1595974701000,也可能是一个滑动窗口周期之前的1595974641000。所以,在获取到当前Bucket的前一个Bucket时,需要根据Bucket的时间窗口开始时间与当前时间戳比较,如果跨了一个周期就是无效的。
声明:公众号、CSDN、掘金的曾用名:“Java艺术”,因此您可能看到一些早期的文章的图片有“Java艺术”的水印。
![]()
本篇内容介绍如何使用r2dbc-mysql驱动程序包与mysql数据库建立连接、使用r2dbc-pool获取数据库连接、Spring-Data-R2DBC增删改查API、事务的使用,以及R2DBC Repository。
消息推送服务主要是处理同步给用户推送短信通知或是异步推送短信通知、微信模板消息通知等。本篇介绍如何使用Spring WebFlux + R2DBC搭建消息推送服务。
IDEA有着极强的扩展功能,它提供插件扩展支持,让开发者能够参与到IDEA生态建设中,为更多开发者提供便利、提高开发效率。我们常用的插件有Lombok、Mybatis插件,这些插件都大大提高了我们的开发效率。即便IDEA功能已经很强大,并且也已有很多的插件,但也不可能面面俱到,有时候我们需要自给自足。
Instrumentation之所以难驾驭,在于需要了解Java类加载机制以及字节码,一不小心就能遇到各种陌生的Exception。笔者在实现Java探针时就踩过不少坑,其中一类就是类加载相关的问题,也是本篇所要跟大家分享的。
订阅
订阅新文章发布通知吧,不错过精彩内容!
输入邮箱,提交后我们会给您发送一封邮件,您需点击邮件中的链接完成订阅设置。