![]()
 云原生实战笔记 专栏收录该内容,点击查看专栏更多内容
云原生实战笔记 专栏收录该内容,点击查看专栏更多内容原创 吴就业 199 0 2024-04-09
本文为博主原创文章,未经博主允许不得转载。
本文链接:https://wujiuye.com/article/40cc5acbee2d4452a1c41562dd2c7905
作者:吴就业
链接:https://wujiuye.com/article/40cc5acbee2d4452a1c41562dd2c7905
来源:吴就业的网络日记
本文为博主原创文章,未经博主允许不得转载。
我们基于scheduler-plugins做二次开发,加了一个插件,实现:当node的实际内存使用已经超过75%的时候,即便node能满足pod的request,我们拦截器也会返回Unschedulable,让Pod变成Padding状态。目的是想要触发Autoscaler自动扩一个node出来。
这个Filter代码如下:
package adapterautoscaler
import (
"context"
"encoding/json"
"fmt"
"github.com/paypal/load-watcher/pkg/watcher"
"k8s.io/klog/v2"
"sigs.k8s.io/scheduler-plugins/apis/config"
"sigs.k8s.io/scheduler-plugins/pkg/trimaran"
"sync"
v1 "k8s.io/api/core/v1"
"k8s.io/apimachinery/pkg/runtime"
"k8s.io/kubernetes/pkg/scheduler/framework"
)
// AdapterAutoscalerArgs holds arguments used to configure AdapterAutoscaler plugin.
type AdapterAutoscalerArgs struct {
// 节点指标超出此阈值拒绝Pod的调度
AutoscalerThreshold AutoscalerThreshold `json:"autoscalerThreshold"`
}
type AutoscalerThreshold struct {
// CPU阈值,0~100 百分比
Cpu int64 `json:"cpu"`
// CPU阈值,0~100 百分比
Memory int64 `json:"memory"`
}
type AdapterAutoscaler struct {
sync.RWMutex
fh framework.Handle
args *AdapterAutoscalerArgs
collector *trimaran.Collector
}
var _ framework.FilterPlugin = &AdapterAutoscaler{}
const (
Name = "AdapterAutoscaler"
)
func (c *AdapterAutoscaler) Name() string {
return Name
}
func convertToAdapterAutoscalerArgs(obj runtime.Object) (*AdapterAutoscalerArgs, error) {
jsonBytes, err := json.Marshal(obj)
if err != nil {
return nil, err
}
customStruct := &AdapterAutoscalerArgs{}
err = json.Unmarshal(jsonBytes, customStruct)
if err != nil {
return nil, err
}
return customStruct, nil
}
func New(obj runtime.Object, handle framework.Handle) (framework.Plugin, error) {
c := &AdapterAutoscaler{
fh: handle,
}
args, err := convertToAdapterAutoscalerArgs(obj)
if err != nil {
return nil, fmt.Errorf("want args to be of type AdapterAutoscalerArgs, got %T", obj)
}
c.args = args
// 这个是拿指标的
collector, err := trimaran.GetFactory().GetCollector(&config.TrimaranSpec{
MetricProvider: config.MetricProviderSpec{
Type: config.KubernetesMetricsServer,
},
})
c.collector = collector
if err != nil {
return nil, err
}
return c, nil
}
func (c *AdapterAutoscaler) Filter(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
metrics, _ := c.collector.GetNodeMetrics(nodeInfo.Node().Name)
var nodeCPUUtilPercent, nodeMemoryUtilPercent float64
var cpuMetricFound, memoryMetricFound bool
for _, metric := range metrics {
if metric.Type == watcher.CPU {
if metric.Operator == watcher.Average || metric.Operator == watcher.Latest {
nodeCPUUtilPercent = metric.Value
cpuMetricFound = true
}
}
if metric.Type == watcher.Memory {
if metric.Operator == watcher.Average || metric.Operator == watcher.Latest {
nodeMemoryUtilPercent = metric.Value
memoryMetricFound = true
}
}
}
podRequest := trimaran.GetResourceRequested(pod)
// 计算cpu是否超过
if cpuMetricFound {
nodeCPUCapMillis := float64(nodeInfo.Node().Status.Capacity.Cpu().MilliValue())
nodeCPUUtilMillis := (nodeCPUUtilPercent / 100) * nodeCPUCapMillis
if (nodeCPUUtilMillis+float64(podRequest.MilliCPU))/nodeCPUCapMillis >= float64(c.args.AutoscalerThreshold.Cpu) {
klog.V(6).InfoS("The CPU reaches the threshold and needs to trigger node expansion.", "nodeName", nodeInfo.Node().Name, "cpuCap", nodeCPUCapMillis, "cpuCur", nodeCPUUtilMillis, "podReq", podRequest.MilliCPU)
return framework.NewStatus(framework.Unschedulable, "The CPU reaches the threshold and needs to trigger node expansion.")
}
}
// 计算内存是否超过
if memoryMetricFound {
nodeMemoryCapBytes := float64(nodeInfo.Node().Status.Capacity.Memory().Value())
nodeMemoryUseBytes := (nodeMemoryUtilPercent / 100) * nodeMemoryCapBytes
if (nodeMemoryUseBytes+float64(podRequest.Memory))/nodeMemoryCapBytes >= float64(c.args.AutoscalerThreshold.Memory) {
klog.V(6).InfoS("The memory reaches the threshold and needs to trigger node expansion.", "nodeName", nodeInfo.Node().Name, "memoryCap", nodeMemoryCapBytes, "memoryCur", nodeMemoryUseBytes, "podReq", podRequest.Memory)
return framework.NewStatus(framework.Unschedulable, "The memory reaches the threshold and needs to trigger node expansion.")
}
}
return framework.NewStatus(framework.Success, "")
}
cpu的阈值我们配置的是45%,内存的阈值我们配置的是75%。
通过实际验证发现,当node已使用内存超过75%,但node剩余的内存满足Pod的request要求,结果是不会扩容node。Pod一直处于Padding-Unschedulable。
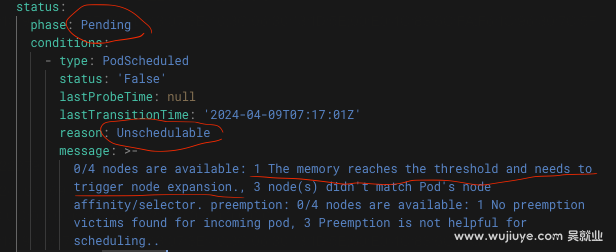
另外,当我们把pod的内存requests调高,让node剩余内存不满足pod的request,发现的确触发扩容了node。
那么,满足Autoscaler扩容node的条件都有什么?
在前面技术调研的时候,我们总结的是只有Pod的状态为Pending,并且处于Pending状态的原因是Unschedulable,才会触发自动扩缩容。这个结论其实也是看了Autoscaler代码找到的。
_, scheduledCondition := podv1.GetPodCondition(&pod.Status, apiv1.PodScheduled)
if scheduledCondition == nil {
return false
}
if scheduledCondition.Status != apiv1.ConditionFalse || scheduledCondition.Reason != "Unschedulable" {
return false
}
但其实并不准确,当我们使用了自定义调度器,实现了自定义的Filter时,我们看到的现象就会跟我们预期的不一样。
“只有Pod的状态为Pending,并且处于Pending状态的原因是Unschedulable”只是触发Autoscaler走ScaleUp(扩容)逻辑,但并不一定会真的扩容节点。
为什么呢?我们阅读Autoscaler的源码找到了答案。
Autoscaler在调用ScaleUp方法之前,会先调用PodListProcessor的Process方法。这里用了责任链模式,按顺序调用每个PodListProcessor,如果调用的PodListProcessor的Process方法返回err,那么责任链会终止,并且返回err。
这个PodListProcessor责任链,一共注册了以下PodListProcessor。
// NewDefaultPodListProcessor returns a default implementation of the pod list
// processor, which wraps and sequentially runs other sub-processors.
func NewDefaultPodListProcessor(predicateChecker predicatechecker.PredicateChecker) *pods.CombinedPodListProcessor {
return pods.NewCombinedPodListProcessor([]pods.PodListProcessor{
NewClearTPURequestsPodListProcessor(),
NewFilterOutExpendablePodListProcessor(),
NewCurrentlyDrainedNodesPodListProcessor(),
NewFilterOutSchedulablePodListProcessor(predicateChecker),
NewFilterOutDaemonSetPodListProcessor(),
})
}
我们需要关注的是NewFilterOutSchedulablePodListProcessor。这个PodListProcessor会从unschedulable的pod列表中,过滤掉可调度的Pod。意思是会模拟一次调度pod,如果模拟调度成功,就过滤掉,还是调度失败的则保留。(对应hinting_simulator.go的TrySchedulePods方法。)
在TrySchedulePods流程中,Autoscaler会遍历所有node,然后调用过滤器插件,看看是否可以把pod调度到某个node上。当所有过滤器插件都返回success时,表示node可以满足这个pod的调度。
filterStatus := p.framework.RunFilterPlugins(context.TODO(), state, pod, nodeInfo)
framework的创建:
framework, err := schedulerframeworkruntime.NewFramework(
context.TODO(),
scheduler_plugins.NewInTreeRegistry(),
&schedConfig.Profiles[0],
schedulerframeworkruntime.WithInformerFactory(informerFactory),
schedulerframeworkruntime.WithSnapshotSharedLister(sharedLister),
)
下面是NewFramework方法:
func NewFramework(ctx context.Context, r Registry, profile *config.KubeSchedulerProfile, opts ...Option) (framework.Framework, error) {
....
f.profileName = profile.SchedulerName
// get needed plugins from config
pg := f.pluginsNeeded(profile.Plugins)
pluginConfig := make(map[string]runtime.Object, len(profile.PluginConfig))
for i := range profile.PluginConfig {
name := profile.PluginConfig[i].Name
if _, ok := pluginConfig[name]; ok {
return nil, fmt.Errorf("repeated config for plugin %s", name)
}
pluginConfig[name] = profile.PluginConfig[i].Args
}
outputProfile := config.KubeSchedulerProfile{
SchedulerName: f.profileName,
PercentageOfNodesToScore: f.percentageOfNodesToScore,
Plugins: profile.Plugins,
PluginConfig: make([]config.PluginConfig, 0, len(pg)),
}
....
}
最终会根据profile参数传递的*config.KubeSchedulerProfile来创建插件。当通过scheduler-config-file启动参数指定KubeSchedulerConfiguration配置文件的时候,就会用启动参数指定的,否则就会用默认的。所以就是用的默认调度器,以及默认调度器使用的插件。
所以,当node已使用内存超过75%,但node剩余的内存满足Pod的request要求,结果是不会扩容node的原因是:我们使用自定义的调度器来调度pod,有自定义的Filter插件。Autoscaler在执行扩容之前,会调用Filter插件,尝试是不是真的没有node满足调度这个pod再去扩容。而默认情况下,Autoscaler拿的是默认的Filter插件,拿不到我们自定义的Filter插件,所以没有走我们的Filter逻辑,所以不会扩容。
我们用GCP的k8s集群,给节点池配置开启了Autoscaler,但是我们没办法配置gcp的Autoscaler的scheduler-config-file参数。
gcp的客服给的方案是,可以考虑一下定义priority class 利用气泡pod占位来提前触发节点池扩容。
但这不是我们想要的。
上面例子的75%内存阈值,是当前node已被使用的内存+新pod要请求的内存>=75%。
假如当前node已使用的内存是50%,而+新pod请求 >= 75%,就要扩,不大于的话就不扩。
“利用气泡pod占位来提前触发节点池扩容”的方式,我们不能预知即将部署的Pod是什么。我们是根据应用拿历史指标数据实时给pod计算requests的,不同应用的pod的内存requests是不同的,无法预知未来的pod的内存requests+node的已使用内存是否超75%。如果不超,扩出来就是资源浪费了。
另外,我们也想到可以通过给pod的requests配置大一些来实现限制node内存使用75%的目标,就是在预测的requests的基础上,加上25%。但这不是我们想要的,会产生资源的浪费。 因此限制node内存使用75%,是根据实际使用限制。而requests虽然预测出来的接近真实值,但毕竟不是真实值,会存在一点资源浪费。
声明:公众号、CSDN、掘金的曾用名:“Java艺术”,因此您可能看到一些早期的文章的图片有“Java艺术”的水印。
![]()
helm在获取values.yaml文件中配置的值时,由于没有对应一个结构体来反序列化yaml,只能使用map来接收,例如map[string]interface{}。可能是将interface{}尝试转成数字,能够转换成功helm就误以为我们需要的是数字了。
自定义资源的Controller创建出来的子资源,子资源创建的子资源(子子资源),如何Watch子子资源的事件?我们以MyDeployment->创建Pod->创建Event,想要watch Pod创建的Event的Create事件为例。
我们在CreateFunc、DeleteFunc、UpdateFunc方法中添加日记,发现这些方法被调用了,但却没有触发控制器的Reconcile方法执行。
本篇简单描述(Autopilot: workload autoscaling at Google)论文中描述的资源request预测算法,不需要理解论文中那复杂的数学公式。
前面《如何获取Pod的CPU和内存指标,使用Grafana Agent收集指标,上传到Prometheus》这篇介绍的指标获取只拿到了cpu使用率,怎么转成cpu使用量呢?
订阅
订阅新文章发布通知吧,不错过精彩内容!
输入邮箱,提交后我们会给您发送一封邮件,您需点击邮件中的链接完成订阅设置。