![]()
 云原生实战笔记 专栏收录该内容,点击查看专栏更多内容
云原生实战笔记 专栏收录该内容,点击查看专栏更多内容原创 吴就业 357 0 2024-02-04
本文为博主原创文章,未经博主允许不得转载。
本文链接:https://wujiuye.com/article/3e359f0644834201b8fbd2488e625f80
作者:吴就业
链接:https://wujiuye.com/article/3e359f0644834201b8fbd2488e625f80
来源:吴就业的网络日记
本文为博主原创文章,未经博主允许不得转载。
在降低增笑的大背景下,如何在保证稳定性的前提下,做到极致压缩k8s资源的使用,实现基础设施真正的按需付费,是我们云原生项目的目标之一。
要实现如Railway这种产品的基础设施按实际使用付费,不能简单的使用云Serverless产品,因为这些产品都有最低限额的要求,例如阿里云最低限制要求Pod至少0.25cpu+0.5g内存,但其实大多数应用这个配额都用不到,大量的时间cpu负载几乎为0,内存消耗可能也就几十M(Java应用除外),大量的低使用率的Pod会造成资源的浪费。
即便对钱不感兴趣,浪费资源也不好。
基础设施按需付费,包括了计算和存储资源,以及网络资源,此次话题重点聚焦在计算资源。
计算资源成本最终体现在购买的云虚拟机上,要实现按实际使用付费,需要从两个不同维度的资源调度着手,一个是节点维度,一个是Pod维度。
目前公有云大多都提供节点动态扩缩容的能力,能够通过利用Spot节点(抢占式虚拟节点),降低集群节点的使用成本。或直接集成在云产品中可直接启用,或通过安装插件的方式启用。
这些需要克金去做实验验证。目前我们针对GKE做了实验,数据后续一篇独立的文章介绍。 实验的结论是,节点扩容时间1分钟左右,缩容的话时间是可以调的,默认是差不多空闲11分钟才完成回收。节点扩容的耗时主要是节点的启动和初始化,这部分自己实现调度器也是优化不了的。因此节点扩缩容这块,直接使用云的功能就可以。
只是,全部使用Spot节点是否是最优解?
基本上公有云上按需的费用总体会比按年合约的费用高。如果想做到极低的成本,完全使用弹性节点是做不到的。但在稳定性前提下,由于团队缺少经验,云产品可谓是短期内可以直接用的最优解。云产品的产品只会考虑Spot池子怎么更好的卖出去,想获得极致的成本优势,长期可能需要考虑调优出一个组合策略。
例如,后期的成本优化策略可以考虑如,统计一整年最低峰期所需要的节点数,第二年按年购买最低所需的节点,统计上月最低所需节点数,按月增量节点(上月最低节点数-上年最低节点数),最后再是弹性节点。实现按年合约节点+按月合约节点+按需节点的节点调度策略。
还有非常难的点,需要考虑节点规格,不能单一的全部一个规格:
Kubernetes的调度器会根据Pod的资源requests和资源limits来进行调度决策。它会选择一个满足Pod的资源request的节点运行Pod,并确保运行时Pod的资源消耗不会超出limits。
如果想要达到资源利用率最大化的目标,使用k8s的默认调度器,只能将requests设置很低,或者不设置,这样可以在每个节点上容纳更多 Pod ,但这样会存在以下问题:
想要实现按需,就是要实现资源超卖,而不是Pod想要多少就给它多少,实际没有使用的就浪费掉了。默认的调度器不支持超卖,除非request非常接近真实值。
那么,是否有开源的解决方案?
阅读了一些网文,发现国内很多互联网企业都在研究在线离线混部这个方向,基于QoS的混部方案。
我们的研究方向:
Koordinator是一款定位为基于QoS的混部调度器,实现离线资源和在线资源的穿插填充使得资源利用率最大化。但我们云原生系统的定位,面向的场景并不存在离线资源,所有资源都为在线资源,解决的是微服务这种场景,那么使用Koordinator是否能够带来收益?
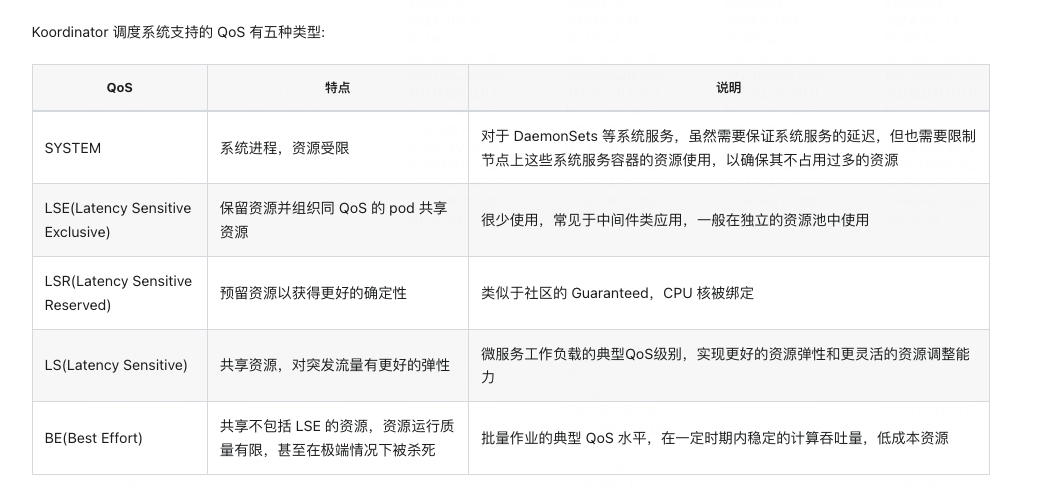
Koordinator定义的五种QoS,由于微服务场景,只会存在LS(Latency Sensitive)这种QoS。基于模版部署的中间件也会是这种QoS。因此,Koordinator提供的能力,我们将只会使用到“负载感知调度”、“负载感知重调度”。
Koordinator节点的资源利用率阈值默认是根据经验配置的,cpu阈值是65%,memory阈值是95%。这个阈值可配置。在实验阶段我们先使用默认的阈值。
实验:
使用go编写用于验证的go-web-demo,占用非常小的cpu和内存资源(实现代码略)。 调request和limit的值看现象。(观察负载感知调度)
部署的yaml模版:
apiVersion: apps/v1
kind: Deployment
metadata:
name: go-web-demo
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: go-web-demo
template:
metadata:
name: go-web-demo
namespace: default
labels:
app: go-web-demo
koordinator.sh/enable-colocation: "true"
spec:
containers:
- name: go-web-demo
image: >-
us-central1-docker.pkg.dev/xxx/yyy/web-demo:v1.0.0
resources:
limits:
cpu: 2000m
memory: 4048Mi
requests:
cpu: 500m
memory: 1024Mi
restartPolicy: Always
terminationGracePeriodSeconds: 30
指定Pod使用Koordinator的调度器,把优先级调到最高、设置QoS为LS。
apiVersion: config.koordinator.sh/v1alpha1
kind: ClusterColocationProfile
metadata:
name: colocation-profile-go
spec:
selector:
matchLabels:
koordinator.sh/enable-colocation: "true"
qosClass: LS
priorityClassName: koord-prod
koordinatorPriority: 9999
schedulerName: koord-scheduler
节点数据:
% kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
gke-nebula-test-cluster-default-pool-2072be92-16rv 252m 26% 1190Mi 42%
gke-nebula-test-cluster-default-pool-2072be92-9wwg 332m 35% 1382Mi 49%
gke-nebula-test-cluster-default-pool-2072be92-vscw 308m 32% 1337Mi 47%
gke-nebula-test-cluster-pool-1-b15967b4-kgpn 236m 25% 1207Mi 43%
gke-nebula-test-cluster-pool-1-b15967b4-x8ql 215m 22% 1189Mi 42%
实验数据:
| 实验项目 | 期望 | 结论 | 备注 |
|---|---|---|---|
| requests > 节点的cap | 能够超卖部署 | ❌ | node可用资源必须>=requests |
| requests < 节点的cap & 副本数增加到5 | 所有pod都能成功 | ❌ | 2副本成功,3副本失败。3副本失败原因:没有节点满足requests,即便已经运行pod实际只占用非常小的资源。 |
| requests cpu=100m,memory=100m。代码中进程启动内存就超过request > 512MB。副本数 = n (100 * n < 所有节点满足n个pod的request < 512*n ) | Pod能正常启动 | ❌ | 有些pod 因request通过,但运行的时候由于没有足够内存,会出现重启。 |
| requests cpu=200m,memory=500m。然后调pod的模拟内存增长的接口,一直涨到node最大内存,但 < limit | pod调度到可用内存更多的节点 | ❌ | pod原地重启。 |
结论: Koordinator不支持基于requests的超卖,使用Koordinator必须设置一个requests值。虽然可以根据经验值自动加上一个非常小的值,然后limit给很大,但内存和cpu使用涨上去后并没有重新调度,如果容器一启动就占用内存超过request,容器就不停的重启。所以依然非常依赖request的设置。
另一个开源项目是scheduler-plugins(https://github.com/kubernetes-sigs/scheduler-plugins),该项目核心能力也是通过实现负载感知调度实现资源最大利用率。不同于Koordinator,scheduler-plugins的侧重点不在在线/离线的混部。相同的是,scheduler-plugins也基于requests调度,非常依赖request的设置。
scheduler-plugins完全基于原生的扩展点编写插件,不需要对k8s集群本身作任何的修改定制。关于k8s的调度框架及框架定义的扩展点可用看官方的介绍:https://kubernetes.io/zh-cn/docs/concepts/scheduling-eviction/scheduling-framework/
我们可能比较关心的是其中的几个插件,这几个插件都是在Scoring阶段负责给节点打分的插件。
scheduler-plugins还提供其它一些项目后期很大可能需要用到的调度器插件,例如:NodeResourcesMostAllocated。
我们重点理解LoadVariationRiskBalancing的算法实现,以及对LoadVariationRiskBalancing和TargetLoadPacking这两个插件做了实验验证,后续两篇文章会分别介绍。
除了实验过程中遇到的一些问题,例如目标负载感知调度插件是使用limits而不是requests、以及缓存数据过期问题。还有一个坑,就是这三个负载感知调度插件,如果指标提供者类型使用KubernetesMetricsServer,那这三个插件不能同时启用,否则会报错(panic: http: multiple registrations for /watcher)。另外,不管指标提供者类型选择什么,每个插件都会单独缓存一份数据,如果需要优化,需要改掉这部分代码。
如果通过控制requests的值来实现超卖,从官方的介绍数据来看,使用Koordinator和scheduler-plugins差别都不大,都需要解决如何收集历史指标数据,基于历史指标计算requests经验值。假设requests经验值非常可靠,那么我们应该选择哪个开源框架。
scheduler-plugins没有太多的概念,基于k8s的调度框架开发,代码很轻量,插件可插拔,可扩展性强。基于我们云原生平台的定位:解决微服务场景下的应用部署,实现按需付费。所以建议是使用scheduler-plugins。
requests值的问题如何解决:
可能的一个方向是,基于Google的论文:Autopilot: workload autoscaling at Google,实现requests的计算。
假如,requests非常的接近真实值,那是否不需要scheduler-plugins了? 还是需要的,即便requests非常的接近真实值:
声明:公众号、CSDN、掘金的曾用名:“Java艺术”,因此您可能看到一些早期的文章的图片有“Java艺术”的水印。
![]()
验证gce的自动缩容时机以及扩容需要的时长:扩容一个节点需要等待多长时间,一个节点在没有Pod的情况下多久后会回收。结合scheduler-plugins框架验证。由于scheduler-plugins只是在Score阶段对节点打分,并未在其它阶段阻止Pod调度到分数为0的Node上,例如基于目标负载感知调度,当所有Node的负载都达到目标负载后,即便节点的requests满足Pod所需,是否能走扩容节点,而不是硬塞到现有节点上。
本篇介绍的内容是scheduler-plugins框架的TargetLoadPacking插件,这是一个k8s调度框架的评分插件。TargetLoadPacking即目标负载调度器,用于控制节点的CPU利用率不超过目标值x%(例如65%),通过打分让所有cpu利用率超过x%的都不被选中。目标负载调度器只支持CPU。
本篇介绍的内容是scheduler-plugins框架的LoadVariationRiskBalancing插件,这是一个k8s调度框架的评分插件,基于request、均值和标准差的K8s负载感知调度器。 我们通过实验去理解和验证该插件实现的负载感知均衡调度算法。
我们在做云原生调度技术调研的时候,为了做实验获取一些数据,需要编写一个demo,支持动态模拟cup使用率和内存使用,所以用go开发了这么一个web程序。
KubeVela于2020年年底开源,距离现在还未满三年时间,是一个非常年轻的产物。KubeVela是非常创新的产物,如OAM模型的抽象设计。所以也并未成熟,除了官方文档,找不到更多资料,在使用过程中,我们也遇到各种大大小小的问题。
由于我们的使用场景是将基础设施资源定义成KubeVela的组件,一个terraform “module”对应的就是一个kubevela的组件,对应terraform-controller的一个Configuration资源。因此导入的最小粒度是组件,即一个terraform “module”。
订阅
订阅新文章发布通知吧,不错过精彩内容!
输入邮箱,提交后我们会给您发送一封邮件,您需点击邮件中的链接完成订阅设置。