![]()
 云原生实战笔记 专栏收录该内容,点击查看专栏更多内容
云原生实战笔记 专栏收录该内容,点击查看专栏更多内容原创 吴就业 224 0 2024-04-01
本文为博主原创文章,未经博主允许不得转载。
本文链接:https://wujiuye.com/article/3e23ccd31c8f4abeae717305a04672da
作者:吴就业
链接:https://wujiuye.com/article/3e23ccd31c8f4abeae717305a04672da
来源:吴就业的网络日记
本文为博主原创文章,未经博主允许不得转载。
论文:Autopilot: workload autoscaling at Google
本篇简单描述此论文中描述的资源request预测算法,不需要理解论文中那复杂的数学公式。
负载分布直方图
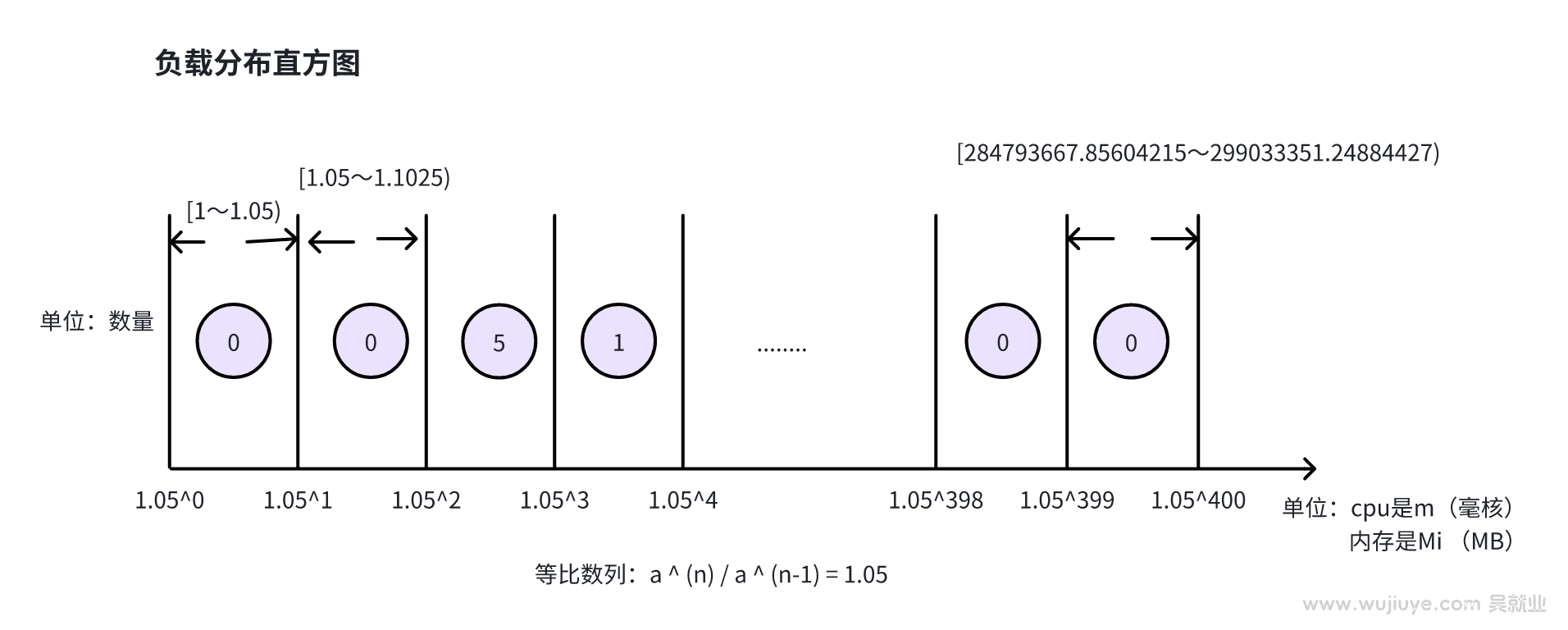
我们以cpu资源为例。直方图的横坐标是毫核,按5%的等比例,划分为400个桶,纵坐标是数量。然后取一段时间的cpu使用量指标,比如原算法中举例取5分钟,获取这5分钟所有采集的cpu使用指标,如果指标是每秒上报一次,那么5分钟就有300个指标,然后将这300个指标根据指标的值放入相对应的桶中,每个桶每放入一个指标那么数量+1。直方图是后续计算的基础。
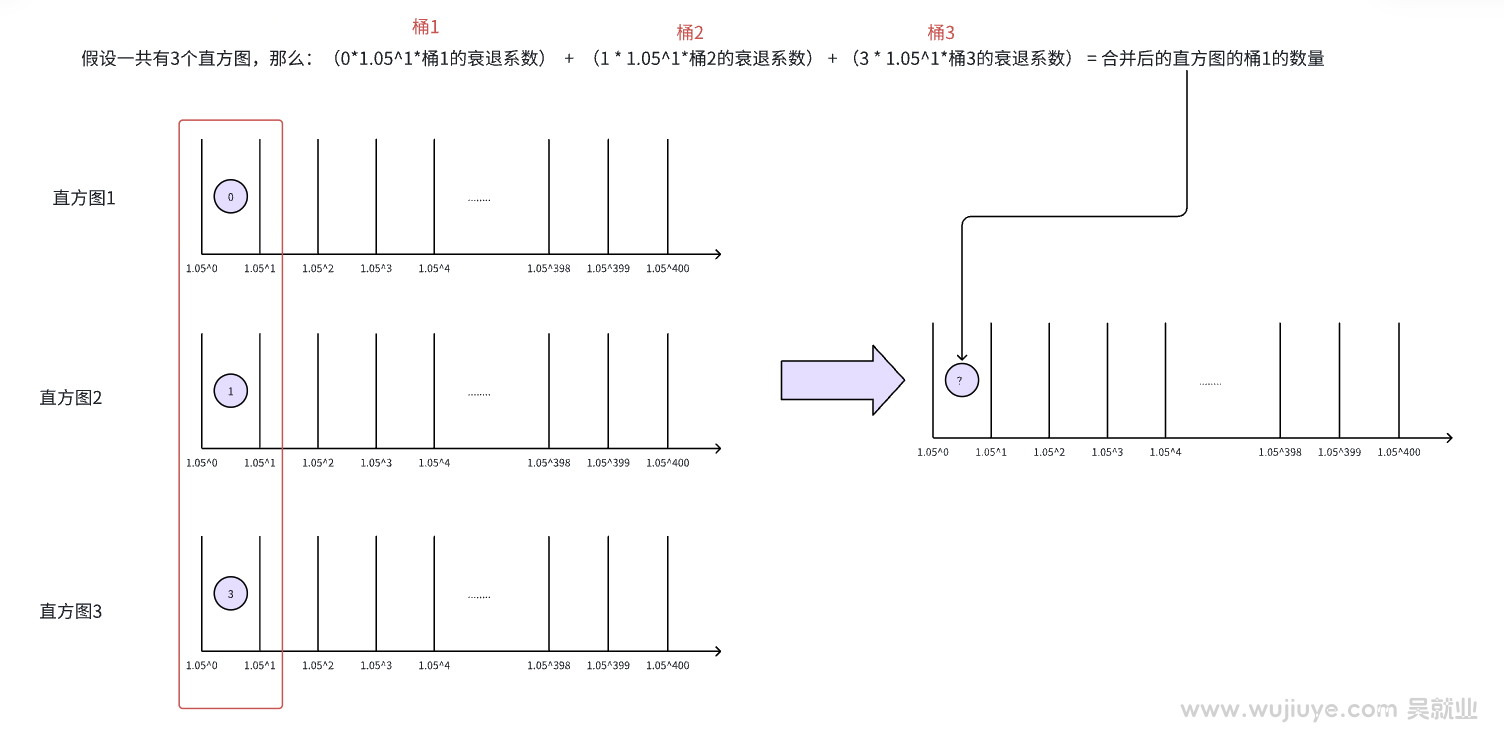
假如我们需要拿12小时的指标数据来预测,一个直方图使用5分钟的数据,那么12小时就对应生成144张直方图。
论文中还引入了衰退系数,衰退系数其实是给直方图加权重,离当前时间越近的指标越有参考价值,所以权重越高,那么对应的直方图的衰退系数越大。
论文中取5分钟指标,按5%等比例(1.05的n次方)划分桶,以及分成400个桶,取多少个小时的数据分成多少个直方图,这些都不是固定的,都是可以调的。
为什么是5%以及400个桶?为什么是5%不清楚,但400个桶是为了覆盖边界值。因为1.05的400次方是299033351.24884427,对于cpu,299033351.24884427约为299033核,对于内存,299033351.24884427约为292024GB。
这个数字对我们来说太大了,假如我们限定单个Pod最大可用的cpu为8核、内存为16G,那么我们可以调整桶的数量为200个。1.05的200次方是17292.58081516013,对于cpu,17292.58081516013约为17核,对于内存,17292.58081516013约为16GB。刚好可以覆盖边界。
算法计算解释
我们最终需要算出S(max)、S(avg)、S(xxline)。S(px)如S(p98)、S(p95)、S(p90)、S(p60)。
对于CPU,如果是一些批处理任务,我们就使用S(avg)作为cpu的request值;如果是在线业务,则根据对于延迟的容忍程度,选择S(95line)或者S(90line)值。
对于内存,一般的任务可以根据对于OOM的忍受程度,选择S(98line)或者S(max),如果是批处理的任务,可以选择S(60line)和1/2*S(max)之间的最大值。
在选定对应的值后,可以再增加10%-15%的安全边界(推荐值越大,应该选择更小的安全边界)。
算法参数微调
声明:公众号、CSDN、掘金的曾用名:“Java艺术”,因此您可能看到一些早期的文章的图片有“Java艺术”的水印。
![]()
我们在CreateFunc、DeleteFunc、UpdateFunc方法中添加日记,发现这些方法被调用了,但却没有触发控制器的Reconcile方法执行。
我们使用自定义的调度器来调度pod,有自定义的Filter插件。Autoscaler在执行扩容之前,会调用Filter插件,尝试是不是真的没有node满足调度这个pod再去扩容。而默认情况下,Autoscaler拿的是默认的Filter插件,拿不到我们自定义的Filter插件,所以没有走我们的Filter逻辑,所以不会扩容。
前面《如何获取Pod的CPU和内存指标,使用Grafana Agent收集指标,上传到Prometheus》这篇介绍的指标获取只拿到了cpu使用率,怎么转成cpu使用量呢?
通常指标和日志收集这两者是一起的,可观测即离不开指标,也离不开日记。当两者都需要的时候,就没必要部署两个DaemonSet了。本篇将两者结合成一个完整的案例,大家可以直接拿去部署使用。
订阅
订阅新文章发布通知吧,不错过精彩内容!
输入邮箱,提交后我们会给您发送一封邮件,您需点击邮件中的链接完成订阅设置。