![]()
 云原生实战笔记 专栏收录该内容,点击查看专栏更多内容
云原生实战笔记 专栏收录该内容,点击查看专栏更多内容原创 吴就业 256 0 2024-02-04
本文为博主原创文章,未经博主允许不得转载。
本文链接:https://wujiuye.com/article/085456ac59254f3592e81f6e3acc8c9f
作者:吴就业
链接:https://wujiuye.com/article/085456ac59254f3592e81f6e3acc8c9f
来源:吴就业的网络日记
本文为博主原创文章,未经博主允许不得转载。
之二:基于request、均值和标准差的K8s负载感知调度器
本篇介绍的内容是scheduler-plugins框架的LoadVariationRiskBalancing插件,这是一个k8s调度框架的评分插件。 我们通过实验去理解和验证该插件实现的负载感知均衡调度算法。 官方文档:https://github.com/kubernetes-sigs/scheduler-plugins/tree/master/kep/61-Trimaran-real-load-aware-scheduling。
LoadVariationRiskBalancing插件是scheduler-plugins提供的负载感知调度的三大插件之一,也是基于requests的负载感知调度器。其目的是实现将负载平均到每个Node,目前支持CPU+Memory,会同时考虑CPU和Memory。
基于requests负载感知调度意味着,LoadVariationRiskBalancing插件不会考虑实际负载,因此依赖request值非常接近真实值才准确,并不是真的动态平衡。
LoadVariationRiskBalancing插件的算法是利用节点负载在某段时间内(滑动窗口)的平均值(M)和标准差(V)这两个指标,假设集群所有节点的CPU利用率的M+V是0.3(30%),那么每个节点的cpu利用率的M+V越接近0.3,得分应该越小。
标准差越接近平均值意味着节点的利用率分布越集中。关于标准差可以参考这篇文章(非常简单易懂):https://zhuanlan.zhihu.com/p/172506729
平均值和标准差都是计算的资源利用率,如CPU利用率的平均值和标准差、内存利用率的平均值和标准差,利用率不会超过100%,取值[0~1],因此平均值和标准差的取值也是[0~1]。
LoadVariationRiskBalancing是分别计算每种资源的得分,再取得分的最小值,例:假设CPU得分0,内存得分10,则节点的最终得分是0。
怎么理解官方文档的这张图:
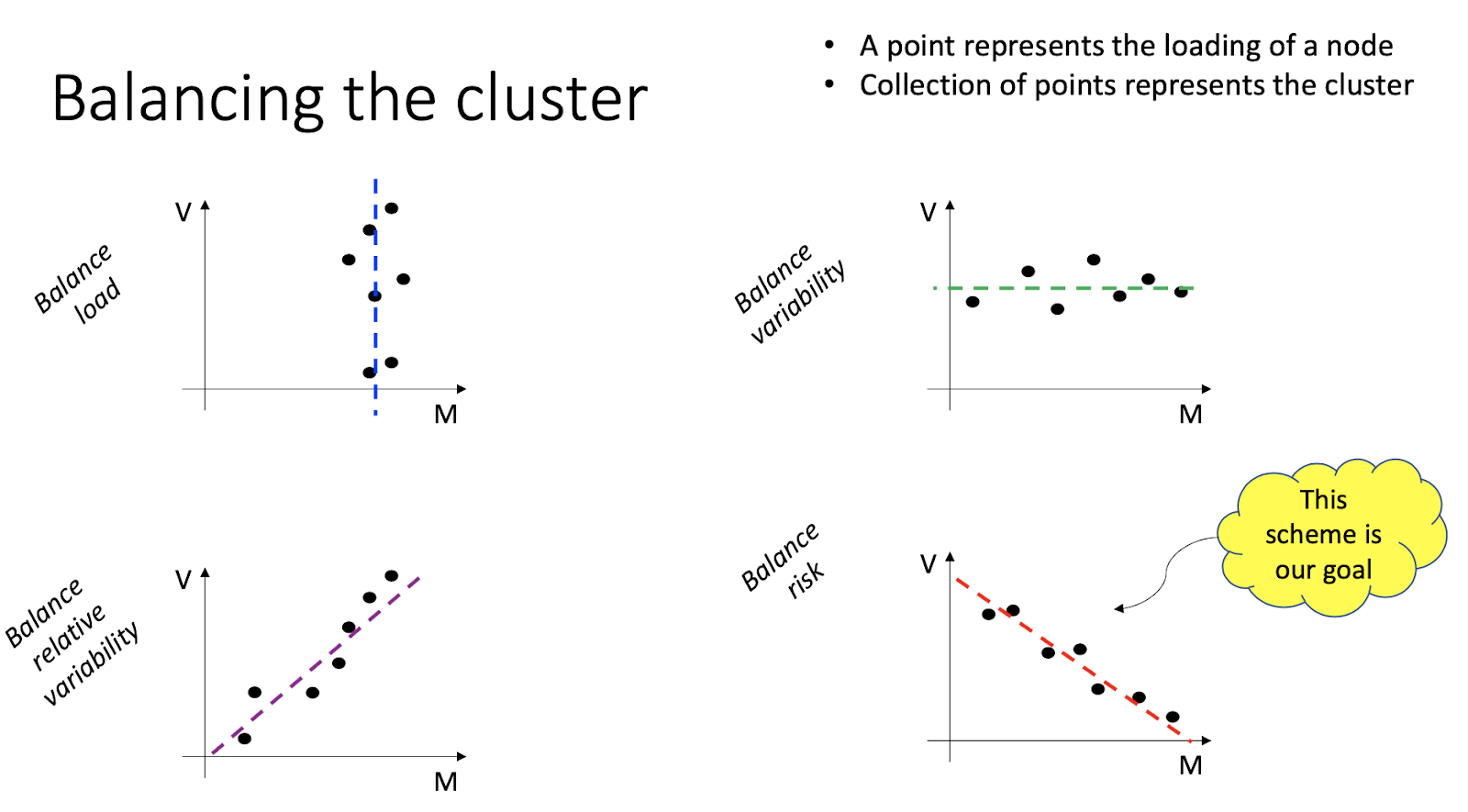
当每个节点的利用率的平均值和标准差符合关系:V + M = c 时(c为整个集群的利用率的平均值加上标准差),说明集群中每个节点的负载接近集群负载。
mu-sigma图的mu指的是均值(μ),sigma指标准差(σ)。
对角线公式:V + M = c ===> sigma + mu <= 1 (100%)
个人对这张图的整体理解:斜线为集群的负载,点为节点的负载。而插件的目标是,节点的负载(M+V)应该无限接近于集群的负载(c)。因集群的整体负载c是固定的(也是集群的M+V),每个节点的M和V是不同的,但一定是M+V=C,才符合期望的目标-负载均衡。也可以反过来理解,斜线c = M+V,根据集群中所有节点的(M,V)画到坐标轴上,这些点应该分布在虚线c附近,即任何一个点(M+V)都无限接近于c。
插件的算法实现: 1. 获取当前要调度的Pod所请求的资源,记为r。 2. 获取当前节点各类资源(CPU、Memory)当前滑动窗口(比如一分钟、或者一个小时)的平均值和标准差。 3. 计算当前节点对各类资源的得分:Si = M + r + V 4. 获取每种类型资源的分数并将其绑定到 [0,1],意思就是最小值为0,最大值为1,小于最小值取最小值,大于最大值取最大值:Si = min(Si,1.0)。 5. 计算当前节点每种资源的优先级得分:Ui = (1-Si) x MaxPriority。 6. 当前节点最终的得分为:U = min(Ui),意思是cpu、内存的分数,哪个低取哪个。
现在来看例子: 假设我们有三个节点N1、N2、N3,要调度的Pod的CPU和内存请求分别为500m和1GB,所有节点容量均为4核、8GB。
第一步:获取Pod请求的资源:
* r(cpu) = 500/4*1000 = 0.125
* r(memory) = 1024/8*1024 = 0.125
第二步:每个节点的当前M和V为:
* N1:
* M(cpu) = 0.8核/4 = 0.2 M(memory) = 1.6G/8 = 0.2
* V(cpu) = 3.2核/4 = 0.8 V(memory) = 4.8G/8 = 0.6
* N2:
* M(cpu) = 2核/4 = 0.5 M(memory) = 6.4G/8 = 0.8
* V(cpu) = 0.04核/4 = 0.01 V(memory) = 0.004G/8 = 0.0005
* N3:
* M(cpu) = 1.2核/4 = 0.3 M(memory) = 3.2G/8 = 0.4
* V(cpu) = 0.4核/4 = 0.1 V(memory) = 0.4G/8 = 0.05
第三步:计算当前节点对各类资源的得分:
* N1:
* Si(cpu) = M(cpu) + r(cpu) + v(cpu) = 0.2 + 0.125 + 0.8 = 1.125 ===> 保留两位小数 = 1.2
* Si(memory) = M(memory) + r(memory) + v(memory) = 0.2 + 0.125 + 0.6 = 0.925 ===> 保留两位小数 = 0.93
* N2:
* Si(cpu) = M(cpu) + r(cpu) + v(cpu) = 0.5 + 0.125 + 0.01 = 0.635 ===> 保留两位小数 = 0.64
* Si(memory) = M(memory) + r(memory) + v(memory) = 0.8 + 0.125 + 0.0005 = 0.9255 ===> 保留两位小数 = 0.93
* N3:
* Si(cpu) = M(cpu) + r(cpu) + v(cpu) = 0.3 + 0.125 + 0.1 = 0.525 ===> 保留两位小数 = 0.53
* Si(memory) = M(memory) + r(memory) + v(memory) = 0.4 + 0.125 + 0.05 = 0.575 ===> 保留两位小数 = 0.58
第四步:取值[0,1]:
* N1:
* Si(cpu) = 1
* Si(memory) = 0.93
* N2:
* Si(cpu) = 0.64
* Si(memory) = 0.93
* N3:
* Si(cpu) = 0.53
* Si(memory) = 0.58
第五步:计算得分(案例中没看懂MaxPriority等于多少,假如为100,那么Ui = (1-Si) * 100,计算结果跟官方案例给的值有点出入,可能是保留两位小数的时机不一样):
* N1:
* Ui(cpu) = (1 - 1) * 100 = 0
* Ui(memory) = (1 - 0.93) * 100 = 7
* N2:
* Ui(cpu) = (1 - 0.64) * 100 = 36
* Ui(memory) = (1 - 0.93) * 100 = 7
* N3:
* Ui(cpu) = (1 - 0.53) * 100 = 47
* Ui(memory) = (1 - 0.58) * 100 = 42
第六步:节点最终的得分:
* N1:
* U = 0
* N2:
* U = 7
* N3:
* U = 42
根据得分,Pod将被调度到N3节点。
通过阅读文档和源码,官方打包的helm不包含TargetLoadPacking、LoadVariationRiskBalancing、LowRiskOverCommitment这三个负载感知调度插件,备注是因为这几个插件需要依赖指标服务。
LoadVariationRiskBalancing and TargetLoadPacking are not enabled by default. as they need extra RBAC privileges on metrics.k8s.io. (来自代码中的注释:https://github.com/kubernetes-sigs/scheduler-plugins/blob/master/manifests/install/charts/as-a-second-scheduler/values.yaml)
因此需要自己修改代码打包。参考官方提供的as-a-second-scheduler这个Chart去改。scheduler-plugins包含Scheduler和Controller,基于负载调度的几个插件并不依赖Controller,因此Controller不需要部署,相关的yaml不需要写。
为访问metrics-api的相关资源授予权限(rbac)。
metrics-api-rbac.yaml:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: sched-plugins-metrics-api-reader-role-binding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: sched-plugins-metrics-api-reader-role
subjects:
- kind: ServiceAccount
name: {{ .Values.scheduler.name }}
namespace: {{ .Release.Namespace }}
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: sched-plugins-metrics-api-reader-role
rules:
- apiGroups:
- "metrics.k8s.io"
resources:
- PodMetrics
- NodeMetrics
verbs:
- get
- list
- watch
插件启用LoadVariationRiskBalancing,禁用默认的Score插件。
plugins:
enabled: ["LoadVariationRiskBalancing"]
disabled: ["NodeResourcesLeastAllocated","NodeResourcesBalancedAllocation"] # 禁用默认的
插件的配置,其中safeVarianceMargin配置项对应算法中的ita值。 这个是对使用量不超过节点容量的置信度系数,涉及到高斯分布,不展开这个话题,这里配置为1即可。
ita这里假设实际使用量遵循高斯分布并遵循68-96-99.5 规则,对使用量不超过节点容量的置信度进行建模。所以当ita得到不同的值时,我们得到不同的不超过容量的置信度。 * ita = 1,我们有 16% 的风险是实际使用量超过节点容量。 * ita = 2,我们有 2.5% 的机会实际使用量超过节点容量。 * ita = 3,我们有 0.15% 的机会实际使用量超过节点容量。默认情况下,我们选择它ita = 1是因为我们希望提高整体利用率。ita可以通过SafeVarianceMargin插件进行配置。
pluginConfig:
- name: LoadVariationRiskBalancingArgs
args:
safeVarianceMargin: 1
metricProvider:
type: KubernetesMetricsServer
启用的插件给一个非常大的权重值,避免存在其它不知道的Score插件影响实验数据。(由于个人没有权限查看集群中启用了哪些Score插件。)
{{- if .Values.plugins.enabled }}
apiVersion: v1
kind: ConfigMap
metadata:
name: scheduler-config
namespace: {{ .Release.Namespace }}
data:
scheduler-config.yaml: |
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
leaderElection:
leaderElect: {{ .Values.scheduler.leaderElect }}
profiles:
# Compose all plugins in one profile
- schedulerName: {{ .Values.scheduler.name }}
plugins:
multiPoint:
enabled:
{{- range $.Values.plugins.enabled }}
- name: {{ title . }}
weight: 10000
{{- end }}
disabled:
{{- range $.Values.plugins.disabled }}
- name: {{ title . }}
{{- end }}
{{- if $.Values.pluginConfig }}
pluginConfig: {{ toYaml $.Values.pluginConfig | nindent 6 }}
{{- end }}
{{- end }}
接着就是通过helm chart将调度器部署到k8s集群。
我们需要查看调度器获取输出的一些日记,因为指标是实时变化的,通过日记获取输出插件运行算法逻辑当时的节点的cpu和内存的使用率和标准差, 这样才有数据验证Pod的调度结果是否符合算法预期。
用于实验的yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: go-web-demo
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: go-web-demo
template:
metadata:
name: go-web-demo
namespace: default
labels:
app: go-web-demo
spec:
containers:
- name: go-web-demo
image: us-central1-docker.pkg.dev/infrastructure-410808/nebula/web-demo:v1.0.2
imagePullPolicy: Always
resources:
limits:
cpu: 2000m
memory: 4048Mi
requests:
cpu: 100m
memory: 100Mi
restartPolicy: Always
terminationGracePeriodSeconds: 30
tolerations:
- key: "sandbox.gke.io/runtime"
operator: "Equal"
value: "gvisor"
effect: "NoSchedule"
schedulerName: scheduler-plugins-scheduler
apply后,得到的调度器日记输出如下。
I0123 01:52:35.418722 1 eventhandlers.go:126] "Add event for unscheduled pod" pod="default/go-web-demo-56b6c86796-27p5h"
I0123 01:52:35.419284 1 scheduling_queue.go:537] "Pod moved to an internal scheduling queue" pod="default/go-web-demo-56b6c86796-27p5h" event="PodAdd" queue="Active"
I0123 01:52:35.419507 1 schedule_one.go:80] "About to try and schedule pod" pod="default/go-web-demo-56b6c86796-27p5h"
I0123 01:52:35.419568 1 schedule_one.go:93] "Attempting to schedule pod" pod="default/go-web-demo-56b6c86796-27p5h"
I0123 01:52:35.421880 1 loadvariationriskbalancing.go:82] "Calculating score" pod="default/go-web-demo-56b6c86796-27p5h" nodeName="gke-nebula-test-cluster-default-pool-521b9803-ncck"
I0123 01:52:35.422109 1 resourcestats.go:72] "Resource usage statistics for node" node="gke-nebula-test-cluster-default-pool-521b9803-ncck" resource="cpu" capacity=940 required=100 usedAvg=21.15 usedStdev=0
I0123 01:52:35.422142 1 analysis.go:58] "Evaluating risk factor" mu=0.12888297872340426 sigma=0 margin=1 sensitivity=1 risk=0.06444148936170213
I0123 01:52:35.422163 1 loadvariationriskbalancing.go:103] "Calculating CPUScore" pod="default/go-web-demo-56b6c86796-27p5h" nodeName="gke-nebula-test-cluster-default-pool-521b9803-ncck" cpuScore=93.55585106382979
I0123 01:52:35.422184 1 resourcestats.go:72] "Resource usage statistics for node" node="gke-nebula-test-cluster-default-pool-521b9803-ncck" resource="memory" capacity=2805.98828125 required=100 usedAvg=779.5381542436246 usedStdev=0
I0123 01:52:35.422237 1 analysis.go:58] "Evaluating risk factor" mu=0.3134504018141557 sigma=0 margin=1 sensitivity=1 risk=0.15672520090707784
I0123 01:52:35.422277 1 loadvariationriskbalancing.go:110] "Calculating MemoryScore" pod="default/go-web-demo-56b6c86796-27p5h" nodeName="gke-nebula-test-cluster-default-pool-521b9803-ncck" memoryScore=84.32747990929221
I0123 01:52:35.421883 1 loadvariationriskbalancing.go:82] "Calculating score" pod="default/go-web-demo-56b6c86796-27p5h" nodeName="gke-nebula-test-cluster-default-pool-521b9803-71zk"
I0123 01:52:35.422483 1 loadvariationriskbalancing.go:119] "Calculating totalScore" pod="default/go-web-demo-56b6c86796-27p5h" nodeName="gke-nebula-test-cluster-default-pool-521b9803-ncck" totalScore=84
I0123 01:52:35.422603 1 resourcestats.go:72] "Resource usage statistics for node" node="gke-nebula-test-cluster-default-pool-521b9803-71zk" resource="cpu" capacity=940 required=100 usedAvg=21.15 usedStdev=0
I0123 01:52:35.422702 1 analysis.go:58] "Evaluating risk factor" mu=0.12888297872340426 sigma=0 margin=1 sensitivity=1 risk=0.06444148936170213
I0123 01:52:35.422806 1 loadvariationriskbalancing.go:103] "Calculating CPUScore" pod="default/go-web-demo-56b6c86796-27p5h" nodeName="gke-nebula-test-cluster-default-pool-521b9803-71zk" cpuScore=93.55585106382979
I0123 01:52:35.422891 1 resourcestats.go:72] "Resource usage statistics for node" node="gke-nebula-test-cluster-default-pool-521b9803-71zk" resource="memory" capacity=2805.98046875 required=100 usedAvg=805.8856221138391 usedStdev=0
I0123 01:52:35.422964 1 analysis.go:58] "Evaluating risk factor" mu=0.32284102908149975 sigma=0 margin=1 sensitivity=1 risk=0.16142051454074988
I0123 01:52:35.423029 1 loadvariationriskbalancing.go:110] "Calculating MemoryScore" pod="default/go-web-demo-56b6c86796-27p5h" nodeName="gke-nebula-test-cluster-default-pool-521b9803-71zk" memoryScore=83.85794854592501
I0123 01:52:35.423101 1 loadvariationriskbalancing.go:119] "Calculating totalScore" pod="default/go-web-demo-56b6c86796-27p5h" nodeName="gke-nebula-test-cluster-default-pool-521b9803-71zk" totalScore=84
I0123 01:52:35.421915 1 loadvariationriskbalancing.go:82] "Calculating score" pod="default/go-web-demo-56b6c86796-27p5h" nodeName="gke-nebula-test-cluster-default-pool-521b9803-r408"
I0123 01:52:35.423269 1 resourcestats.go:72] "Resource usage statistics for node" node="gke-nebula-test-cluster-default-pool-521b9803-r408" resource="cpu" capacity=940 required=100 usedAvg=39.48 usedStdev=0
I0123 01:52:35.423318 1 analysis.go:58] "Evaluating risk factor" mu=0.14838297872340425 sigma=0 margin=1 sensitivity=1 risk=0.07419148936170213
I0123 01:52:35.423364 1 loadvariationriskbalancing.go:103] "Calculating CPUScore" pod="default/go-web-demo-56b6c86796-27p5h" nodeName="gke-nebula-test-cluster-default-pool-521b9803-r408" cpuScore=92.58085106382978
I0123 01:52:35.423453 1 resourcestats.go:72] "Resource usage statistics for node" node="gke-nebula-test-cluster-default-pool-521b9803-r408" resource="memory" capacity=2805.98828125 required=100 usedAvg=1086.6674462019755 usedStdev=0
I0123 01:52:35.423517 1 analysis.go:58] "Evaluating risk factor" mu=0.4229053464447627 sigma=0 margin=1 sensitivity=1 risk=0.21145267322238134
I0123 01:52:35.423543 1 loadvariationriskbalancing.go:110] "Calculating MemoryScore" pod="default/go-web-demo-56b6c86796-27p5h" nodeName="gke-nebula-test-cluster-default-pool-521b9803-r408" memoryScore=78.85473267776186
I0123 01:52:35.423562 1 loadvariationriskbalancing.go:119] "Calculating totalScore" pod="default/go-web-demo-56b6c86796-27p5h" nodeName="gke-nebula-test-cluster-default-pool-521b9803-r408" totalScore=79
I0123 01:52:35.424599 1 default_binder.go:53] "Attempting to bind pod to node" pod="default/go-web-demo-56b6c86796-27p5h" node="gke-nebula-test-cluster-default-pool-521b9803-71zk"
I0123 01:52:35.434890 1 round_trippers.go:553] POST https://10.116.0.1:443/api/v1/namespaces/default/pods/go-web-demo-56b6c86796-27p5h/binding 201 Created in 9 milliseconds
I0123 01:52:35.435213 1 handler.go:133] "updateCache" pod="default/go-web-demo-56b6c86796-27p5h"
I0123 01:52:35.435348 1 eventhandlers.go:197] "Add event for scheduled pod" pod="default/go-web-demo-56b6c86796-27p5h"
I0123 01:52:35.435161 1 eventhandlers.go:171] "Delete event for unscheduled pod" pod="default/go-web-demo-56b6c86796-27p5h"
I0123 01:52:35.435657 1 scheduling_queue.go:1120] "Event received while pods are in flight" event="AssignedPodAdd" numPods=1
I0123 01:52:35.435748 1 cache.go:404] "Finished binding for pod, can be expired" podKey="e4a23d77-72a4-44f8-9876-d5a61b7e398e" pod="default/go-web-demo-56b6c86796-27p5h"
I0123 01:52:35.436133 1 schedule_one.go:286] "Successfully bound pod to node" pod="default/go-web-demo-56b6c86796-27p5h" node="gke-nebula-test-cluster-default-pool-521b9803-71zk" evaluatedNodes=3 feasibleNodes=3
从日记中拿到的数据如下: Cap表示节点总的可用的资源上限,UsedAvg表示滑动窗口内节点资源的平均使用量,UsedStdev表示滑动窗口内节点资源使用的标准差。
* ncck节点:
* Cap(cpu): 940m Cap(memory): 2805.98M
* UsedAvg(cpu): 21.15m UsedAvg(memory): 779.53M
* UsedStdev(cpu): 0 UsedStdev(memory): 0
* 71zk节点:
* Cap(cpu): 940m Cap(memory): 2805.98M
* UsedAvg(cpu): 21.15m UsedAvg(memory): 805.88M
* UsedStdev(cpu): 0 UsedStdev(memory): 0
* r408节点:
* Cap(cpu): 940m Cap(memory): 2805.98M
* UsedAvg(cpu): 39.48m UsedAvg(memory): 1086.66M
* UsedStdev(cpu): 0 UsedStdev(memory): 0
由当前调度的Pod请求的资源cpu是100m,内存是100M,简化公式,将第二步、第三步、第四步合并一起计算各资源得分Si:
* ncck节点:
* Si(cpu): M(cpu) + r(cpu) + V(cpu) = (21.15 + 100 + 0) / 940m = 0.1288 (与日记输出的mu符合)
* Si(memory): M(memory) + r(memory) + V(memory) = (779.53 + 100 + 0) / 2805.98 = 0.3134 (与日记输出的mu符合)
* 71zk节点:
* Si(cpu): (21.15 + 100 + 0) / 940 = 0.1288 (与日记输出的mu符合)
* Si(memory): (805.88 + 100 + 0) / 2805.98 = 0.3228 (与日记输出的mu符合)
* r408节点:
* Si(cpu): (39.48 + 100 + 0) / 940 = 0.1483 (与日记输出的mu符合)
* Si(memory): (1086.66 + 100 + 0) / 2805.98 = 0.4229 (与日记输出的mu符合)
根据公式第五步、第六步计算节点得分:
* U(ncck节点): min(1 - Si(cpu) * 100 = 87.12, 1 - Si(memory) * 100 = 68.66) = 87 (结果舍弃小数部分,四舍五入)
* U(71zk节点): min(1 - Si(cpu) * 100 = 87.12, 1 - Si(memory) * 100 = 67.72) = 87 (结果舍弃小数部分,四舍五入)
* U(r408节点): min(1 - Si(cpu) * 100 = 85.17, 1 - Si(memory) * 100 = 57.71) = 85 (结果舍弃小数部分,四舍五入)
计算结果与日记输出的得分有些出入:U(ncck节点) = 84 、 U(71zk节点) = 84、U(r408节点) = 79。 从代码找到,计算结果*了一个风险系数。
risk := (mu + sigma) / 2
这行代码实际是 Si / 2,因为这里的mu是 UsedAvg + podReq计算出来的。计算各节点资源的risk为:
* U(ncck节点):
* risk(cpu): 0.1288 / 2 = 0.064
* risk(memory): 0.3134 / 2 = 0.1567
* U(71zk节点):
* risk(cpu): 0.1288 / 2 = 0.064
* risk(memory): 0.3228 / 2 = 0.1614
* U(r408节点):
* risk(cpu): 0.1483 / 2 = 0.0741
* risk(memory): 0.4229 / 2 = 0.2114
计算结果与日记输出的risk值相符。
把risk值代入公式重新计算节点得分:
* U(ncck节点): min(1 - risk(cpu) * 100 = 87.12, 1 - risk(memory) * 100 = 68.66) = 84 (结果舍弃小数部分,四舍五入)
* U(71zk节点): min(1 - risk(cpu) * 100 = 87.12, 1 - risk(memory) * 100 = 67.72) = 84 (结果舍弃小数部分,四舍五入)
* U(r408节点): min(1 - risk(cpu) * 100 = 85.17, 1 - risk(memory) * 100 = 57.71) = 79 (结果舍弃小数部分,四舍五入)
根据最终得分,应选择ncck节点或71zk节点,实际选择71zk节点,符合预期。
把副本数增加到10,观察各节点的Pod分布。
各节点负载情况:
wujiuye@wujiuyedeMacBook-Pro cloud_native % kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
gke-nebula-test-cluster-default-pool-521b9803-71zk 47m 5% 1178Mi 41%
gke-nebula-test-cluster-default-pool-521b9803-ncck 54m 5% 1127Mi 40%
gke-nebula-test-cluster-default-pool-521b9803-r408 88m 9% 1520Mi 54%
符合预期。
把71zk节点上的某个pod的cpu调到5,使得总体的节点cpu在10%以内,等待一个滑动窗口时间(不具体是多少的情况下,等个几分钟)。
各节点负载情况:
wujiuye@wujiuyedeMacBook-Pro cloud_native % kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
gke-nebula-test-cluster-default-pool-521b9803-71zk 94m 10% 1176Mi 41%
gke-nebula-test-cluster-default-pool-521b9803-ncck 53m 5% 1114Mi 39%
gke-nebula-test-cluster-default-pool-521b9803-r408 84m 8% 1518Mi 54%
随后把副本数增加到15个,观察Pod分布情况。
各节点负载情况:
wujiuye@wujiuyedeMacBook-Pro cloud_native % kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
gke-nebula-test-cluster-default-pool-521b9803-71zk 101m 10% 1183Mi 42%
gke-nebula-test-cluster-default-pool-521b9803-ncck 56m 5% 1146Mi 40%
gke-nebula-test-cluster-default-pool-521b9803-r408 85m 9% 1521Mi 54%
算法同时考虑cpu和内存,由于ncck节点的内存消耗接近71zk节点的内存消耗,所以节点得分是差别不大的,结果符合预期。
通过简单的实验验证了算法的准确性,但由于实验数据还是太过简单,实际效果还需真实场景验证。
声明:公众号、CSDN、掘金的曾用名:“Java艺术”,因此您可能看到一些早期的文章的图片有“Java艺术”的水印。
![]()
云原生的优势在于利用Serverless技术优化基础设施成本,要求应用启动速度快且内存占用低。然而,Java应用在自动弹性扩缩容和内存消耗方面存在问题。文章以部署个人项目的视角,通过比较小明使用Go语言和小聪使用Java语言开发的博客系统的部署情况,展示了Java的启动速度慢和内存占用大的不适应性。
验证gce的自动缩容时机以及扩容需要的时长:扩容一个节点需要等待多长时间,一个节点在没有Pod的情况下多久后会回收。结合scheduler-plugins框架验证。由于scheduler-plugins只是在Score阶段对节点打分,并未在其它阶段阻止Pod调度到分数为0的Node上,例如基于目标负载感知调度,当所有Node的负载都达到目标负载后,即便节点的requests满足Pod所需,是否能走扩容节点,而不是硬塞到现有节点上。
本篇介绍的内容是scheduler-plugins框架的TargetLoadPacking插件,这是一个k8s调度框架的评分插件。TargetLoadPacking即目标负载调度器,用于控制节点的CPU利用率不超过目标值x%(例如65%),通过打分让所有cpu利用率超过x%的都不被选中。目标负载调度器只支持CPU。
在降低增笑的大背景下,如何在保证稳定性的前提下,做到极致压缩k8s资源的使用,实现基础设施真正的按需付费,是我们云原生项目的目标之一。要实现如Railway这种产品的基础设施按实际使用付费,不能简单的使用云Serverless产品,因为这些产品都有最低限额的要求,例如阿里云最低限制要求Pod至少0.25cpu+0.5g内存,但其实大多数应用这个配额都用不到,大量的时间cpu负载几乎为0,内存消耗可能也就几十M(Java应用除外),大量的低使用率的Pod会造成资源的浪费。
我们在做云原生调度技术调研的时候,为了做实验获取一些数据,需要编写一个demo,支持动态模拟cup使用率和内存使用,所以用go开发了这么一个web程序。
KubeVela于2020年年底开源,距离现在还未满三年时间,是一个非常年轻的产物。KubeVela是非常创新的产物,如OAM模型的抽象设计。所以也并未成熟,除了官方文档,找不到更多资料,在使用过程中,我们也遇到各种大大小小的问题。
订阅
订阅新文章发布通知吧,不错过精彩内容!
输入邮箱,提交后我们会给您发送一封邮件,您需点击邮件中的链接完成订阅设置。