![]()
 Dubbo实战经验分享与源码分析 专栏收录该内容,点击查看专栏更多内容
Dubbo实战经验分享与源码分析 专栏收录该内容,点击查看专栏更多内容原创 吴就业 160 0 2019-09-22
本文为博主原创文章,未经博主允许不得转载。
本文链接:https://wujiuye.com/article/03c60a46eeb6419db10389aa28305a95
作者:吴就业
链接:https://wujiuye.com/article/03c60a46eeb6419db10389aa28305a95
来源:吴就业的网络日记
本文为博主原创文章,未经博主允许不得转载。
本篇文章写于2019年09月22日,从公众号|掘金|CSDN手工同步过来(博客搬家),本篇为原创文章。
第一次将分布式技术应用到实际项目中就遇到分布式事务的问题,好在不是那种严格要求双写一致性的事务问题。
我了解的分布式事务解决方案有两种,分别是XA和TCC,今天要分享的是,我如何使用TCC处理项目中分布式事务问题。
我遇到的问题,其实跟电商系统的减库存是一样的性质,无非就是对“产品”的“量”进行控制。好比你在淘宝开了家店铺,卖iphone11的手机壳,假设你购进10个手机壳,这10个手机壳就是库存量,每当有一个用户下单就必须要减去相应的库存,这就是事务的双写一致性问题。假设,用户下单成功而扣减库存失败,就会出现超卖现象,但实际只有10个手机壳,下单了11个,不够怎么发货?再假设,用户下单一个手机壳,可库存扣减了两次,那么就会出现剩余库存卖不出去的情况。无论是哪种假设成立,都会是头疼的问题。
在广告系统中,也需要对广告投放的量做控制,与电商系统的库存一样,假设广告主投放一个广告规定每日只有一千的预算,那超出的部分广告主不会给你钱,渠道又找你要钱。好在并没有像银行转账那种事务强一致性的要求,我们无需确保百分百的一致性,但必须要追求百分之九九的一致性,所以我在项目中使用TCC来解决我遇到的问题。
为了更容易理解,我还是以电商系统商品库存为例。
假设,库存我是用redis存储的,用户下单之后由订单服务生成订单,并调用库存服务扣减库存,同时还要发送订单到消息中间件,由物流服务消费安排发货。
我们来结合下面的图理解。我对电商系统不了解,只能结合我在项目中遇到的场景打个比方。
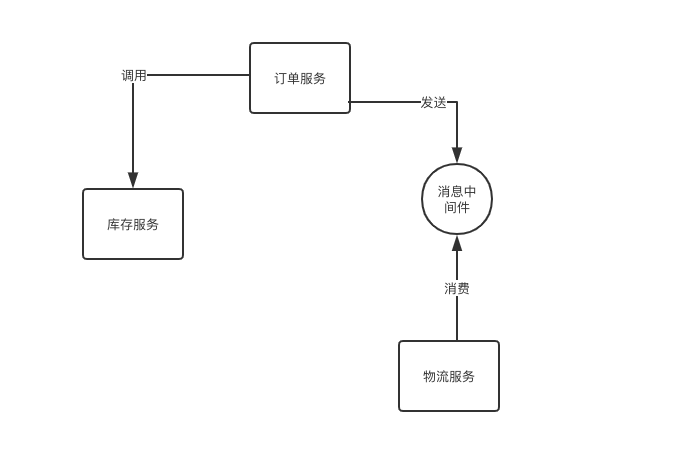
你可能会有疑惑,既然已经使用消息中间件,为何其它服务不都通过消息中间件解决事务问题。
并非所有服务都适合使用消息中间件来解决事务问题,比如例子中,扣减库存对数据的实时性要求非常高。比如秒杀系统,如果使用消息中间件消费扣减库存,一秒钟的间隔出现多大的商品库存数据误差。而像下单完成后由物流服务安排出货,这种对实时性没有要求的场景,就可以使用消息中间件。
不知道你们是不是经常使用支付宝交话费,我习惯使用支付宝交话费,方便到连手机号码都不需要输。有时候支付成功后,1分钟内话费就到帐了,但有时候等了一个多小时才到帐,我都怀疑过是不是系统出了bug,需不需要打人工客服电话处理。
本例中,除用到消息中间件外,还有一个问题,库存使用的redis。redis无法支持本地事务,因为redis的事务没有回滚功能。我将一个扣减库存的接口拆分为三个接口,对应try、confirm、cancel,实现两阶段提交。将一个接口分成三个,虽然confirm与cancel只有一个会被调用,但也多出一次接口的调用,增加库存服务的负担。
关于两阶段提交,第一阶段调用try方法扣减库存时,并非真正的扣减库存,而是完成一系列业务逻辑,最后记录一条扣减某商品库存的log,冻结相应库存;第二阶段调用confirm方法时,才是真正的去扣减库存,或者调用cancel方法将预写数据回滚。
允许我简单的介绍下TCC。TCC即try-confirm-cancel两阶段事务方案,第一阶段预写数据,第二阶段提交写或者回滚。这与关系型数据库事务在理解层面上没有区别。但无论是XA还是TCC,都无法百分百的解决分布式事务问题。
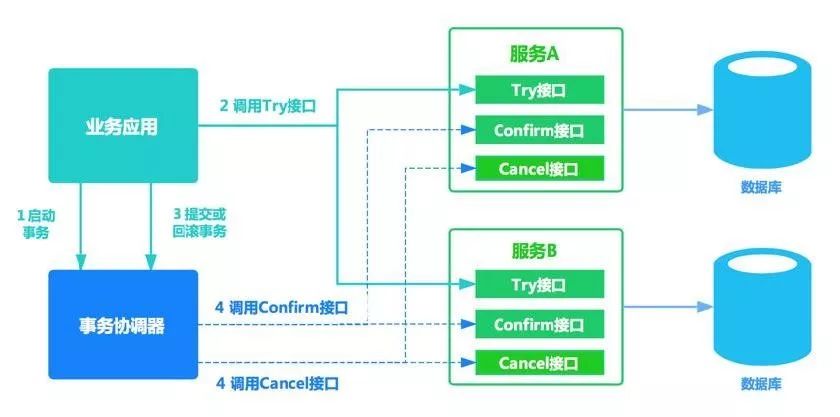
(图片来源百度搜索)
在网上随便找了张图,这是TCC最完整的实现方案,而我只是简单的将事务发起者(对应图中的“业务应用”)与事务协调器的作用一起实现了。
为什么说TCC也无法百分百的解决分布式事务问题。
假设在try阶段,事务A(本地事务,后文皆指)预写成功,而事务B(本地事务,后文皆指)预写失败,注意,是预写。就可以调用cancel回滚事务A。但是,如果在try阶段,事务A、B都预写成功,然而第二阶段,事务A提交成功,但事务B提交失败,就会出现问题,事务A已经无法回滚。
对于上述这种情况,解决方案就是重试,库存已经冻结,重试对其它事务并无影响。
我所理解的重试,不是在服务消费方,也不是图中的事务协调器,而是在服务提供方,由服务提供方定时检测是否存在未完成写的已提交事务重试完成写。
我所理解的TCC,第一阶段的预写,必须是已经完成了业务逻辑,只是写不是真正的写,而是写log,冻结预扣减的库存,最后第二阶段事务提交才是真正的写,将预写数据真正写回需要写的地方。
第二阶段提交写可能会出现问题,库存已经不够了,虽然预写时库存是够的。并发情况很常见,多个分布式事务同时提交写。所以冻结的作用就是,每个事务判断库存是否足够时,需要将库存剩余量减去冻结的库存量。对于本例来说是无法实现的,因为redis没有事务,无法控制预写时的一系列操作的原子性。
如果两个事务都是操作数据库就很好解决这个问题,我的实现思路,库存表的设计如下:
库存表:Id,商品id,库存量,多个分布式事务的预扣(冻结)量
预写log表:id,事务id,预扣库存量,状态(是否已提交)。
还是回归实际业务场景,对于本例的扣减库存的try-confirm-cancel接口,我的简单实现如下。
/**
* 预写自减
* @param tranId 分布式事务id
*/
@Override
public void trySub(String tranId, Object params) {
// 执行业务逻辑
......
// 由于没有协调器,60分钟后自动释放
{ // 无法实现本地事务的原子性,即下面两条命令要么都执行成功,要么都执行失败
valueRedisTemplate.incr(冻结资源key,1);
valueRedisTemplate.setex(tranId, “incr xxx 1” , 3600);
}
}
/**
* 提交自减事务,也要实现幂等,避免对同一事务多次消费
* @param tranId 分布式事务id
* @return
*/
@Override
public void confirmSub(String tranId) {
String value = valueRedisTemplate.get(tranId);
// 避免重复消费:del成功说明事务还没提交,可以提交,否则不重复提交;
if (valueRedisTemplate.del(tranId) > 0) {
try {
// 无法实现本地事务的原子性,即下面两条命令要么都执行成功,要么都执行失败
// 执行真正的扣库存
valueRedisTemplate.incr(商品id库存key,-1);
valueRedisTemplate.incr(解除资源冻结key,-1);
} catch (Exception e) {
// 进入重试
}
}
}
/**
* 取消自增事务
* @param tranId 分布式事务id
*/
@Override
public void cancelSub(String tranId) {
if(valueRedisTemplate.get(tranId)!=null){
// 无法实现本地事务的原子性,即下面两条命令要么都执行成功,要么都执行失败
valueRedisTemplate.incr(解除资源冻结key,-1);
valueRedisTemplate.del(tranId);
}
}
在订单服务调用如下
try{
subService.trySub(tranId, params);
mqService.sendOrder(order);
subService.confirmSub(tranId);
}catch(Exception e){
subService.cancel(tranId);
}
由于mqService.sendOrder(order);发送消息到mq无法实现try-confirm-cancel,所以对于该分布式事务来说,已经不是真正的分布式事务。但mq发送失败会抛异常,当发送消息到mq抛出异常时,就说明发送mq在第一阶段失败了,整个分布式事务需要回滚。
能解决的问题是,由于服务重启或其它问题导致mq没发送或发送失败时,也不会真正去减库存。缺陷是,发送mq成功时,由于服务重启或者网络问题没能调用confirmSub提交事务,也没能调用cancel回滚,导致数据不一致,所以为什么需要一个第三方TCC协调器来负责调用confirm与cancel。
在考虑分布式事务解放方案时,不要忘了接口的幂等性才是实现分布式事务的关键。dubbo调用失败会有重试机制,为避免底层netty调用接口第一次调用成功,但由于网络原因超时时间内服务消费方未能接收到服务提供方的响应,结果进行重试第二次调用(或者第二次调用了集群的另一个服务),导致结果多扣了一次库存。
接口幂等性导致的问题,明明接口调用成功,服务提供方已经执行成功,却因为服务消费方收不到响应或超时放弃就认为失败进行重试,导致重复扣减库存。所以,必须实现接口的幂等性,可由生成的全局唯一分布式事务id实现。
简单说,引入TCC能解决第一阶段预写时就失败的问题,比如业务判断参数错误,库存不够,这次写是不能执行成功的,整个分布式事务都要回滚。而第二阶段,事务a提交失败,也能将事务a和事务b一起回滚(假设a在b之前提交),如果是事务a提交成功,而b提交失败,那就重试到事务b提交成功为止。
总的来说,分布式事务接口需要实现幂等性,开启事务时生成全局唯一的分布式事务id;分布式事务的提交和回滚由事务协调器负责;try预写阶段完成业务逻辑,并锁定预写资源,保证多个分布式事务之间不影响;第一个事务提交成功,第二个事务失败,则由协调器重试提交;如果已提交的事务真正写失败,则由业务接口提供方定时重试;对于数据库有事务的支持,而对于redis除非能保证只使用一条原子性命令完成一个本地事务。
当然,由于例子中使用了mq,也使用redis,实际上并未能真的实现TCC,没有本地事务的支持何谈分布式事务。对于我实际面对的业务场景比扣库存负责的多,而且整个“扣库存”业务逻辑都是redis操作,无法实现TCC中真正的预写。
声明:公众号、CSDN、掘金的曾用名:“Java艺术”,因此您可能看到一些早期的文章的图片有“Java艺术”的水印。
![]()
SPI全称是Service Provider Interface,直译就是服务提供者接口,是一种服务发现机制,是Java的一个内置标准,允许不同的开发者去实现某个特定的服务。Dubbo的SPI并非使用Java提供的SPI,完全是自己实现的一套SPI机制,并对其进行了增强,如通过字节码实现动态代理类。
笔者最近的一次重构项目选择用dubbo去实现服务间的调用,选择dubbo作为分布式的RPC远程服务调用框架,但笔者在使用的过程中遇到了很多疑难问题,网上搜不到一篇能解决我疑问的文章,无奈,只能选择自己从源码中寻找答案。
Java8提供的流式编程Stream,相信大家每天都在用。但是读过源码的,我猜也没有几个,包括我。只是最近使用上遇到些问题,不得不去深入了解,所以我花了点时间粗略看了一下,但关于并行流的逻辑我也没理解清楚。
老项目一直在使用AWS的ElastiCache的Redis集群服务,为什么突然要自己部署集群呢。理由只有一个,贵了。对的,使用AWS的Redis集群服务,每个月要300$以上的费用,这成本是高了些,并且现在这个平台的并发量不高,缓存的数据量也只有1G多,确实贵了。
订阅
订阅新文章发布通知吧,不错过精彩内容!
输入邮箱,提交后我们会给您发送一封邮件,您需点击邮件中的链接完成订阅设置。